 2025 中国开源年度报告
2025 中国开源年度报告数据篇
一、数据篇概览
1.1 开源发展目标:从全球愿景到中国实践
开源已从一种软件开发模式,演变为支撑数字文明的基础性公共基础设施。为系统评估开源对社会、经济与技术进步的综合价值,中国科协联合国咨商开源创新专委会在 2025 年正式提出 “开源发展目标”(Open Source Development Goals, OSDGs) ——一套受联合国可持续发展目标(SDGs)启发、专为开源生态设计的全球性评估框架。
OSDGs 旨在回答一个根本问题:开源如何为更公平、高效、可持续的世界作出贡献? 它超越了传统的“代码数量”或“Star 数”等单一维度,转而关注开源在促进知识共享、赋能边缘群体、推动绿色计算、保障数字主权等方面的深层价值。该框架包含三大支柱:
- 环境(Planet):评估开源在能效优化、资源节约和绿色技术创新中的作用;
- 社会(People):衡量开源在教育普惠、技能提升、社区包容性和人才多样性方面的成效;
- 治理(Governance):考察开源在标准共建、规则透明、协作公平和生态健康度方面的机制建设。
今年,《2025 中国开源年度报告》首次全面采纳 OSDGs 框架,对数据篇进行结构性重构,立足中国实际,将全球愿景转化为本土行动指南。本报告聚焦以下核心关切:
- 中国开发者在全球开源协作网络中的角色与贡献质量;
- 开源如何助力中国新质生产力发展与关键技术自主可控;
- 区域协调发展背景下,各省市开源生态的差异化路径与协同潜力;
- 高校与青年开发者作为“未来贡献者”的培养机制与参与深度。
通过将中国实践嵌入 OSDGs 的全球坐标系,我们既可对标国际先进水平,又能凸显中国特色的开源发展路径,为政策制定、产业布局与社区建设提供兼具战略高度与实操价值的洞察。
1.2 指标体系与数据来源
为科学、客观地衡量 OSDGs 各维度目标的实现程度,本报告构建了一套三层递进式开源评估指标体系,该体系源自《2025 全球开源发展报告》,并结合中国生态特点进行本地化适配。该体系以“行为—质量—影响力”为逻辑主线,逐层深化:
1.2.1 第一层:活跃度(Activity)
活跃度是评估的基础,用于筛选出真正参与协作的开发者与项目。本报告定义五类核心贡献行为作为活跃度的构成要素:
- OI(Open Issue):创建议题,提出问题或需求;
- ID(Issue Discussion):参与议题讨论,提供反馈或解决方案;
- OPR(Open Pull Request):提交代码合并请求,贡献代码或文档;
- PRR(Pull Request Review):评审他人代码,保障质量;
- MPR(Merge Pull Request):合并代码请求,完成集成。
仅当一个账号在统计周期内完成上述任一行为,才被认定为“活跃开发者”。此标准有效排除了仅“Star”或“Fork”等低参与度行为的干扰,确保后续分析基于真实协作数据。
1.2.2 第二层:贡献质量(Quality of Contribution)
在识别活跃参与者后,需进一步判断其贡献的价值。本报告采用 “社区 OpenRank”算法,聚焦于单个项目内部的协作网络。该算法根据行为类型(如 MPR 权重大于 OI)、互动对象(与核心维护者的互动权重更高)、被采纳率等维度,计算开发者在特定项目中的相对贡献质量,从而识别出真正的“核心贡献者”。
1.2.3 第三层:影响力(Influence)
最终,需将个体或组织的贡献置于全球开源生态中进行定位。本报告采用 “全域 OpenRank”算法,构建覆盖数十亿节点的全球开发者-项目协作图谱。该算法借鉴 PageRank 思想,认为“被高质量贡献者关注或协作的项目/开发者,其自身影响力也更高”。通过此算法,可生成跨项目、跨组织、跨地域的统一影响力排名,用于评估企业、高校、行政区乃至国家在全球开源生态中的战略地位。
1.2.4 数据来源与处理
本研究的数据采集与分析依托于 OpenDigger 开源项目 及其对应的 在线服务平台,所有行为数据均通过该平台进行系统性采集与处理。
时间窗口为 2025 年 1 月 1 日至 2025 年 12 月 31 日。依托 OpenDigger 平台构建的多维标签体系(包括 34 个中国省级行政区、1,000+ 企业、200+ 技术领域等),本报告实现了从全球宏观趋势到中国微观生态的无缝穿透分析。全部原始数据与分析代码均已开源,确保研究的透明、可验证与可复现。
OpenDigger 是一个致力于推动全球开源生态透明化与可度量化的开放数据基础设施。项目最初由 X-lab 开放实验室发起,在木兰开源社区孵化成长,其技术架构融合了来自高校、科研院所及企业等多方机构的研究成果。为推动开源生态的透明化、可度量与可持续发展,OpenDigger 正在构建一个开放、中立、多方参与的全球共治架构,致力于成为服务全球开源治理的公共数字基础设施(Public Digital Infrastructure)。
在本报告中,核心评估指标——OpenRank 北极星指标(OpenRank North Star Metric)正是基于 OpenDigger 构建的多维度数据体系而设计。OpenRank 是全球首个系统性、原创性的开源标准体系,被工信部列入《关于公布 2024 年团体标准应用推广典型案例》(工信部科函〔2025〕19 号),体现了其权威性和实践价值。
如图所示,OpenRank 指标体系从“开发者-项目”二维视角出发,构建了包含 OpenRank 贡献度 (Contribution Impact) 与 OpenRank 影响力(Influence)两大维度的象限模型,全面刻画个体与项目的开源参与质量与社会价值。
同时,OpenRank 作为 OpenDigger 平台的核心输出之一,具备以下五大特征:
- 全局视角:综合考量开发者在多个平台、多个项目中的行为轨迹;
- 注重影响力:不仅关注贡献数量,更强调技术传播力与协作网络地位;
- 鼓励协作互动:重视 Issue、Pull Request、评论等交互行为;
- 鼓励长期参与:引入时间衰减机制,激励持续性贡献;
- 具有鲁棒性与高度可扩展性:支持跨平台、跨语言、跨领域的统一评估。
相关详细文档可参见 OpenDigger 用户文档。
本报告结合 GitHub、Gitee、AtomGit / GitCode 和 GitLab 等多个开源协作平台的数据进行分析。截至 2025 年年底,GitHub 平台的活跃开发者累计达到 2,500 万;国内 Gitee / AtomGit / GitCode 等平台的活跃开发者规模累计接近 1,000 万;GitLab 平台的活跃开发者累计接近 80 万。在活跃仓库规模方面,GitHub 已超过 3,600 万个,国内 Gitee / AtomGit / GitCode 等平台超过 2,600 万个,GitLab 接近 73 万。
相较于往年的中国开源年度报告来说,今年的一个重要变化是加入了模型平台数据,以 Hugging Face 为代表,更完整地观察全球与本土开源模型生态的演进。截至 2025 年底,Hugging Face 平台累计接近 234 万个模型、47 万个模型发布者,分别较 2024 年底增长 117 万个和 21 万个,增幅分别为 100% 和 80%。与此同时,截至 2025 年底,平台累计已有超 16 万名开发者发生过协作行为、累计触及超 21 万个模型,分别较 2024 年增长约 60% 和 140%。这里的“协作行为”主要指开发者在模型仓库中发生的发帖或评论、编辑和表情反馈等互动行为。这说明以 Hugging Face 为代表的模型平台,已不只是模型发布与分发平台,而正在演化为同时承载模型供给扩张、开发者协作互动与生态反馈循环的关键基础设施。
1.3 数据篇整体结构
为系统呈现 OSDGs 框架下中国开源生态的全景图景,本数据篇由四大核心部分构成,形成“观测—对标—深挖—前瞻”的完整逻辑闭环:
第二部分:开源生态观测体系 本部分构建四张动态地图,从空间、主体、技术与人才四个维度描绘中国开源生态的基本盘:
- 开源活跃地图:基于 Activity 和 OpenRank 指标,展示全球主要国家/地区的开源参与热度;
- 开源贡献地图:基于 Activity 和 OpenRank 指标,揭示高价值贡献者的地理分布与组织归属;
- 开源技术地图:追踪人工智能、云原生、基础软件、RISC-V 等关键领域的技术演进与项目集群分布;
- 开源人才地图:结合开发者标签、开发者成长轨迹与 OSPP 活动数据,刻画新生代开源力量的来源、流动与成长路径。
第三部分:开源影响力排行榜 在观测基础上,本部分发布四大权威榜单,树立标杆、引导方向:
- 行政区划影响力排行榜:量化评估全球和中国各省市在全球开源生态中的综合影响力,服务区域数字经济发展评估;
- 开源企业影响力排行榜:涵盖国内外科技企业与非营利组织,反映其开源战略投入、项目主导力与社区领导力;
- 开源项目影响力排行榜:基于全域 OpenRank 指标,评选年度最具影响力的开源项目,覆盖基础软件、AI 框架、开发工具、数据库等多个类别,全面反映项目的生态位势与协作广度;
- 新势力开源项目排行榜:聚焦 2025 年期间首次发布且表现突出的新项目,捕捉创新火种与未来潜力。
第四部分:开源专题分析
针对年度关键议题,开展深度穿透式研究:
- AI 大模型年度分析:基于 Hugging Face 全域数据,系统解析大模型开源生态、协作新模式、许可证挑战、国产替代路径及社区治理新范式;
- 开源之夏(OSPP)年度分析:基于近年开源之夏活动数据,评估高校人才培养成效、项目完成质量与社区反哺机制,探索开源教育可持续发展路径。
整体而言,2025 年数据篇以 OSDGs 为纲,以三大板块为体,既承接全球共识,又深耕中国土壤,力求为所有关心中国开源未来的读者提供一份权威、透明、可行动的年度参考。
二、开源生态观测体系
2.1 开源活跃地图
2.1.1 开篇定位:开源参与的“地理基座”
开源活跃地图(Open Source Activity Map, A-Map)旨在刻画全球开发者参与开源的地理分布与群体规模,反映开源生态的参与广度与社区基础,是衡量“谁在参与、从何而来”的核心观测维度。
本小节采用活跃开发者人数(Number of Active Contributors, NAC)作为核心指标,真实反映各国在开源生态中的参与规模与活跃基座。新增活跃开发者是指此前从未在平台活跃、在本年度内首次开始活跃的开发者。
2.1.2 核心发现:规模跃升、格局重塑
全球活跃开发者规模突破新高
截至 2025 年年底,根据 GitHub Octoverse Report 数据显示,全球开发者总量已突破 1.8 亿(其中新增开发者超过 3,600 万)。其中,近十年在 GitHub 平台的活跃开发者(Active Developer)累计达到 2,493 万;国内 Gitee / AtomGit / GitCode 等平台的活跃开发者规模接近 1,000 万;GitLab 平台的活跃开发者规模接近 80 万。
2025 年全球新增活跃开源开发者规模超过 500 万,其中 GitHub 平台新增规模 301 万,Gitee / AtomGit / GitCode 等平台新增规模整体达到 200 万(根据问卷篇调研数据去重后),GitLab 平台新增超 12 万。
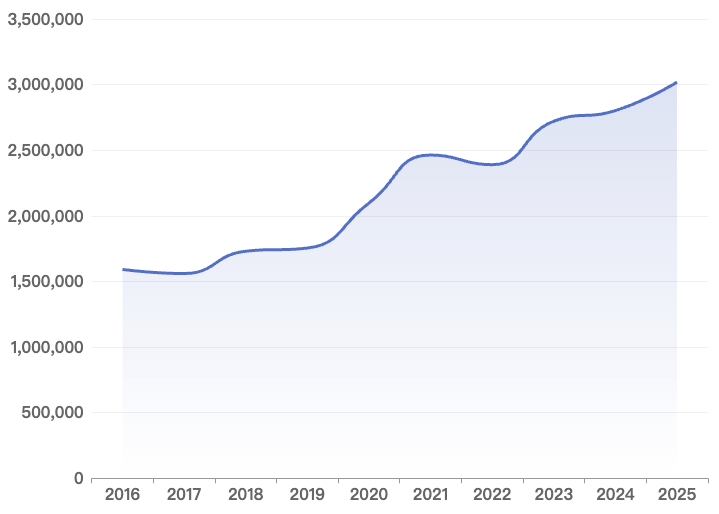
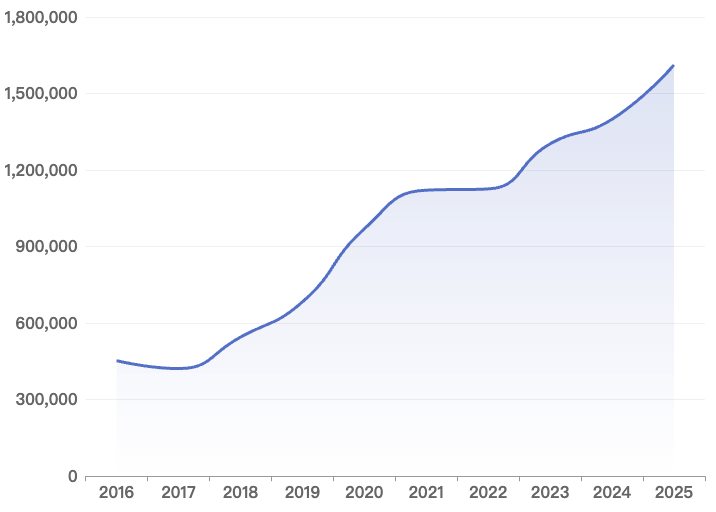
如图 2.1 所示,从整体趋势来看,不同平台呈现出较为明显的发展阶段特征:
- GitHub:新增活跃开发者数量持续增长,从 158 万增长至 301 万,十年间实现规模翻倍。其中,2025 年新增活跃开发者为 301 万,较 2024 年的 280 万增长 7.73%,体现出全球开源生态持续扩张并逐渐进入成熟发展阶段。
- Gitee:平台新增活跃开发者在 2017 年小幅回落至 42.2 万后,持续增长至 2025 年的 161.2 万,增长势头显著。
- AtomGit / GitCode:作为 2023 年 9 月启动的新平台(并在 2025 年 11 月底完成了合并),目前仅有三年数据,但增长迅速,2025 年新增活跃开发者 25 万,较 2024 年的 5 万增长 335%,呈现出新兴平台典型的早期快速扩张特征。
- GitLab:平台新增活跃开发者数量在 2016—2022 年总体保持快速增长并于 2022 年达到峰值,随后在 2023—2024 年明显回落,2025 年略有恢复,但整体上反映出平台开发者增量进入高位调整阶段。
进一步结合 GitHub 与 Gitee 的整体变化,可以观察到以下现象:
- 2020 年以来新增开发者规模进入快速增长通道,表明开源生态的整体活跃度和参与规模持续提升。
- 2020—2021 年增长率处于高位,随后虽仍保持正增长,但增幅有所回落。
- 这一变化可能与 疫情因素有关:疫情期间远程办公与线上协作需求增加,推动开发者参与度提升;随着 2022 年后疫情逐步缓解,增长率回归常态,整体呈现出“高速增长后趋于稳健”的发展特征。
表 2.1 2016—2025 全球新增活跃开发者增长率(GitHub 平台)
| 年份 | 数值 | 同比增长率 |
|---|---|---|
| 2017 | 1,559,743 | -1.98% |
| 2018 | 1,729,865 | 10.91% |
| 2019 | 1,754,328 | 1.41% |
| 2020 | 2,096,742 | 19.52% |
| 2021 | 2,463,159 | 17.48% |
| 2022 | 2,389,476 | -2.99% |
| 2023 | 2,721,043 | 13.88% |
| 2024 | 2,802,137 | 2.98% |
| 2025 | 3,018,649 | 7.73% |
2.1.3 中国稳居全球开源第一梯队
如表 2.1 所示,截至 2025 年底,GitHub 平台 中国的活跃开发者超 210 万,规模稳居 全球第三,已成为全球开源生态的关键力量;如果加上国内 Gitee / AtomGit / GitCode 等平台,整体数量预计超过 350 万(根据问卷篇调研数据去重),位居 全球第二。与此同时,美国与印度分别位列前两位,开发者规模优势明显,持续引领全球开源创新与社区贡献格局。德国、英国、加拿大等欧洲及北美国家亦保持较高活跃度,整体呈现出以北美为核心、亚洲快速崛起、欧洲稳健发展的多极化分布特征。
表 2.2 截至 2025 年底各国活跃开发者数量 Top 10(GitHub 平台)
| 排名 | 国家 | 总体数量(万) |
|---|---|---|
| 1 | 美国 | 508.42 |
| 2 | 印度 | 254.87 |
| 3 | 中国 | 210.63 |
| 4 | 巴西 | 149.38 |
| 5 | 德国 | 116.02 |
| 6 | 英国 | 101.76 |
| 7 | 加拿大 | 86.11 |
| 8 | 法国 | 71.59 |
| 9 | 俄罗斯 | 61.84 |
| 10 | 波兰 | 41.22 |
从各国新增活跃开发者变化趋势(图 2.2)可以看出,各个地区区域特征显著:
- 美国进入成熟期:新增活跃开发者从 11.8 万降至 3.4 万,增量放缓但存量庞大,反映其生态高度成熟;
- 中国出现结构性拐点:2016–2018 年稳步上升,2020 年后持续回落,2025 年新增仅约 1.5 万(而 Gitee / AtomGit / GitCode 等平台新增数量,根据问卷篇调研数据去重后则超过了 100 万);
- 印度领跑全球增长:新增活跃开发者从 2.1 万增至 5.4 万,十年增长近 167%,稳居全球第一,成为南亚开源主力;
- 新兴市场快速崛起:巴西(1.3 万 → 3.4 万)、印尼(0.2 万 → 0.9 万)等国增速迅猛,成为拉美与东南亚开源新引擎;
- 欧洲整体保持稳定:德、英、法、加等国新增量维持在 1–2 万区间,俄罗斯小幅波动,整体进入平稳发展阶段。
趋势总结:全球开源参与格局正从“单极主导”加速转向“多极并进”,区域多样性显著增强,开源生态日益呈现“南升北稳、东进西固”的新态势。
2.2 开源贡献地图
2.2.1 开篇定位:贡献即责任,共建即未来
全球开源贡献地图(Global Open Source Contribution Map, C-Map)旨在衡量各国与各类主体在开源生态中的实质性技术投入与协作深度,是判断其是否从“技术使用者”迈向“生态共建者”的关键标尺。
本小节采用 OpenRank 贡献度(OpenRank Contribution Impact)作为核心指标,聚焦代码提交、评审反馈、问题修复等高质量协作行为,超越活跃度与贡献量的数量统计,真实反映技术共建的深度与可持续性。OpenRank 影响力体现了开发者在开源生态中的位置优势,但 OpenRank 贡献度 则更可以体现开发者在开源生态中真实的贡献多少。
2.2.2 核心发现:多极共治加速,中美模式分化
基于 OpenRank 指标体系与 GitHub 2016–2025 年十年数据,全球开源贡献格局呈现三大结构性转变。
2.2.3 增长速度分化加剧,新兴市场迎来爆发期
全球开源开发者的 OpenRank 贡献度(Contribution Impact)和 OpenRank 影响力(Influence)在 2016—2025 年的变化趋势如下面两幅图所示。
从整体趋势看,OpenRank 贡献度数据在 2016–2024 年间稳步增长,由 747 万 提升至 2,052 万,增长路径更为平滑,反映出开发者深度贡献能力持续增强。但 2025 年同样下降至约 1,926 万,虽降幅相对温和,拐点趋势已然显现。
相比之下,OpenRank 影响力数据在 2016–2023 年间持续快速增长,由约 2,635 万 上升至 9,088 万,实现三倍以上扩张,生态活跃度与网络影响规模显著提升。2020 年后增长进一步加速,但 2024 年开始回落,2025 年明显降至约 5,640 万,出现阶段性收缩。
2025 年两项指标出现同步下滑,且贡献度降幅更为显著,可能意味着协作网络的连接密度与互动频率有所减弱,开发者在跨主体协作中的实际贡献强度下降,从而使贡献度相较于影响力呈现更为明显的回调。随着生成式 AI 工具的广泛应用,部分原本依赖社区协作完成的任务被技术手段替代,在提升个体开发效率的同时,客观上可能降低了开发者之间的互动需求与协作频率。此外,部分中国开发者由 GitHub 转向 GitCode、Gitee 等国内平台,多数项目由小规模团队甚至个体完成,协作网络的外部连接度相对减弱。上述因素叠加,最终在 2025 年体现为整体指标的阶段性回落。
全球各国开源开发者的 OpenRank 贡献度(Contribution Impact)和 OpenRank 影响力(Influence)变化趋势如下面两幅图所示。
从图中可以看出,开源生态正经历“规模扩张”与“区域格局重塑”的双重演进:
- 增长动能强劲:印度 OpenRank 贡献度十年增长 6 倍,巴西超 5 倍,中国达 3 倍,反映新兴市场对开源技术的快速吸纳与本土化创新;
- 影响力格局重塑:美国仍居首位,德国稳居欧洲第一,中国、印度快速上升,形成“美欧引领、亚非拉追赶”的新态势;
- 贡献趋势逆转:美国贡献度于 2021 年达峰后持续回落,而中国贡献度持续攀升,成为全球增长最快的主要力量之一。
- 中国加大贡献投入:与影响力相较,可以看到中国开发者更注重深度贡献,以美国约三分之一的开发者影响力,却达到了美国开源开发者贡献度总量的近 50%,并且仍在以 7.54% 的增速快速发展,已与其他国家拉开了距离。
洞察:由于美国开发者的贡献度在 2020 年后出现了下滑,2025 年中美贡献度增速差已超过 10%,按目前的发展态势,7 年后中国开发者的贡献度将超过美国成为全球第一。
表 2.3 2025 全球 OpenRank 贡献度 Top 10
| 排名 | 国家名称 | OpenRank 影响力 | 增长率 |
|---|---|---|---|
| 1 | 美国 | 297,884 | -14.70% |
| 2 | 中国 | 254,963 | -1.89% |
| 3 | 德国 | 79,742 | -10.38% |
| 4 | 英国 | 58,146 | -12.86% |
| 5 | 加拿大 | 44,731 | -11.92% |
| 6 | 法国 | 44,108 | -12.87% |
| 7 | 印度 | 40,482 | -13.13% |
| 8 | 荷兰 | 26,241 | -15.11% |
| 9 | 波兰 | 20,284 | -13.32% |
| 10 | 瑞士 | 17,642 | -15.12% |
表 2.4 2025 全球 OpenRank 影响力 Top 10
| 排名 | 国家名称 | OpenRank 影响力 | 增长率 |
|---|---|---|---|
| 1 | 美国 | 1,789,364 | -9.68% |
| 2 | 德国 | 625,814 | -7.75% |
| 3 | 中国 | 611,892 | -15.20% |
| 4 | 英国 | 441,392 | -10.30% |
| 5 | 印度 | 392,517 | -14.65% |
| 6 | 法国 | 341,508 | -9.63% |
| 7 | 加拿大 | 312,094 | -10.12% |
| 8 | 巴西 | 268,315 | -13.51% |
| 9 | 荷兰 | 195,842 | -8.83% |
| 10 | 日本 | 185,409 | -11.55% |
综合表 2.3(影响力)与表 2.4(贡献度)可见,2025 年前十国家在两类指标上均出现不同程度的同比下降,呈现出全球开源生态活跃度阶段性回调的特征。
- 美国在影响力与贡献度两项指标上仍保持显著领先,但降幅相对明显;
- 中国在影响力指标中的降幅相对较小,表现出一定稳定性,而在贡献度维度回落幅度更为突出,反映出网络结构层面的相对韧性与实际产出强度下降之间的差异。
- 欧洲主要国家整体呈现同步回落态势,波动区间相对集中,国家间排序未发生显著变化。
2.2.4 全球贡献流向重构:从中心化到多极流动
开源生态的协作边界正持续扩展,全球开发者贡献的流动格局也发生深刻变化。通过分析 2025 年跨国贡献数据,桑基图(图 2.7)揭示了国家间开源资源的动态流转路径,呈现出从“单极主导”向“多向流动”演进的趋势。
桑基图(Sankey Diagram)展示各国间开源项目贡献度流动,左侧为贡献输出国家,右侧为包括中美在内的 10 个国家的贡献输入。从全球流向看,美国依然是开源协作网络的核心枢纽,但其角色已从“主导者”转向“赋能者”——作为开源资源的“净输出国”,美国开发者对德国、英国、法国等欧洲技术强国的项目保持显著贡献,同时深度参与印度、以色列等新兴生态的技术共建,体现出强大的跨区域影响力与生态辐射力。
相比之下,中国更多扮演“接收者”角色,其开发者高度活跃于 Linux、Kubernetes、PyTorch 等由美国主导的国际主流项目,贡献密度位居全球前列。然而,反向流动则明显不足:中国本土项目获得的海外实质性参与仍十分有限,反映出当前全球开源协作中依然存在的“中心-边缘”结构。
这一流动格局的背后,是不同国家在开源治理理念、生态开放性与全球吸引力上的深层差异。尤其在中美两大技术力量之间,这种差异进一步演化为两种截然不同的贡献模式。为进一步揭示两国在开源共建逻辑上的根本分歧,我们对比了中美自主发起开源项目的全球贡献分布情况。
2.2.5 中美在全球自主开源项目贡献中占据主导地位
如表 2.5 数据显示:
- 美国项目高度全球化:2024 年,其本土开发者贡献仅占 38.21%,超过六成来自海外,其中中国(7.81%)、德国(6.84%)、加拿大(5.06%)等国家深度参与,形成真正意义上的全球协同开发网络,展现出卓越的“生态引力”;
- 中国项目仍以内循环为主:本土贡献高达 79.14%,海外贡献整体微弱,仅美国(6.27%)、加拿大(1.59%)等少数国家有微量参与,国际化协作程度在全球排名第 10,凸显“自建自用”的阶段性特征。
- 深层含义:未来开源竞争的核心,已从“人才输出”转向“生态引力”——能否吸引全球开发者深度共建,成为衡量国家开源领导力的关键标准。
表 2.5 2025 中美两国自主开源项目全球贡献分布 Top 10(左:中国,右:美国)
| 中国主导开源项目全球贡献分布 | 美国主导开源项目全球贡献分布 | ||||||
|---|---|---|---|---|---|---|---|
| 排名 | 国家 | OpenRank 贡献度 | 贡献度占比 | 排名 | 国家 | OpenRank 贡献度 | 贡献度占比 |
| 1 | 中国 CN | 25,103.68 | 79.14% | 1 | 美国 US | 119,864.31 | 38.21% |
| 2 | 美国 US | 1,986.42 | 6.27% | 2 | 中国 CN | 24,518.77 | 7.81% |
| 3 | 加拿大 CA | 503.16 | 1.59% | 3 | 德国 DE | 21,472.93 | 6.84% |
| 4 | 德国 DE | 427.91 | 1.35% | 4 | 英国 GB | 18,612.48 | 5.92% |
| 5 | 新加坡 SG | 414.82 | 1.31% | 5 | 加拿大 CA | 15,874.62 | 5.06% |
| 6 | 印度 IN | 371.04 | 1.18% | 6 | 印度 IN | 13,702.15 | 4.36% |
| 7 | 捷克 CZ | 231.42 | 0.73% | 7 | 法国 FR | 11,488.36 | 3.66% |
| 8 | 保加利亚 BG | 176.88 | 0.56% | 8 | 荷兰 NL | 7,084.93 | 2.26% |
| 9 | 瑞典 SE | 186.05 | 0.59% | 9 | 波兰 PL | 5,844.71 | 1.86% |
| 10 | 英国 GB | 168.73 | 0.53% | 10 | 瑞士 CH | 5,982.44 | 1.91% |
中美在开源领域的互动呈现显著不对称性:一方面,中国开发者广泛参与并推动美国主导项目的发展;另一方面,美国开发者对中国项目的反向贡献极为有限。这种“单向融入”现象,既体现了中国技术社群的学习能力与执行力,也暴露出我国在构建全球认同、提升项目开放性与治理透明度方面的短板。
这一结构性挑战,也促使中国必须从“规模贡献”迈向“全球共治”,在国家战略、平台基建与人才培育协同发力的基础上,突破“内循环”瓶颈,真正实现从“使用开源”到“贡献开源”再到“引领开源”的跃迁。
2.2.6 全球贡献集中度持续下降,多极共治格局加速形成
进一步,给出 2016—2025 年各国活跃开发者 OpenRank 影响力总数占全球总量的比例情况。
如图 2.8 所示,过去十年全球开源影响力逐渐走向分散:
- 前五大国家 OpenRank 影响力总和从 2016 年的 58.46% 降至 2025 年的 48.93%,下降近 10 个百分点;
- 德国、中国、印度等国贡献占比稳步提升,推动生态从“美国单极主导”向“多元协同共治”转型。
趋势解读:集中度下降并非美国衰落,而是全球协作网络深化的自然结果,标志着开源创新的参与主体更加多元、权力结构更趋平衡。
2.3 开源技术地图
2.3.1 开篇定位:技术即战场,开源即前沿
全球开源技术地图(Global Open Source Technology Map, T-Map)旨在刻画各技术领域在开源生态中的活跃度、成长性与影响力分布,反映全球技术创新的动能演变与战略重心迁移,是研判“哪些领域在爆发、谁在定义技术前沿”的核心观测工具。
本小节采用活跃开源仓库数(Number of Active Open Source Repositories, NAOSR)与 OpenRank 影响力(OpenRank Influence)作为核心指标,前者衡量特定技术领域的项目活跃密度与生态繁荣度,后者基于协作网络结构量化该领域中主体的技术话语权与社区影响力。
2.3.2 核心发现:AI 引领爆发,多点协同演进
截至 2025 年年底,根据 GitHub Octoverse Report 数据显示,当前 GitHub 上共有 3.95 亿个公开和开源仓库(public & open source repositories),相比去年增加 7,200 万个,增速显著。其中,近十年在 GitHub 平台的活跃仓库累计达到 3,488 万;国内 Gitee / AtomGit / GitCode 等平台的活跃仓库规模接近 2,700 万;GitLab 平台的活跃仓库规模接近 70 万。
2025 年全球活跃仓库规模超过 1,100 万,其中 GitHub 平台新增规模 590 万,Gitee / AtomGit / GitCode 等平台新增规模整体达到 500 万,GitLab 平台新增超 11 万。
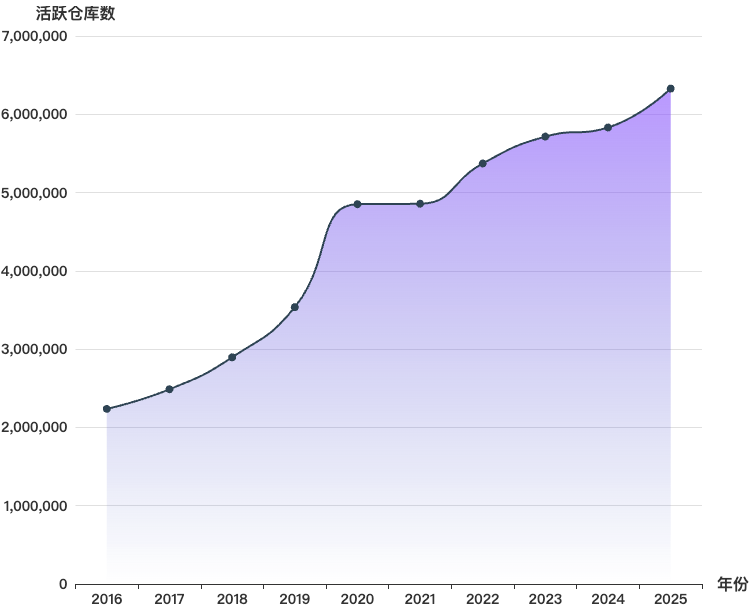
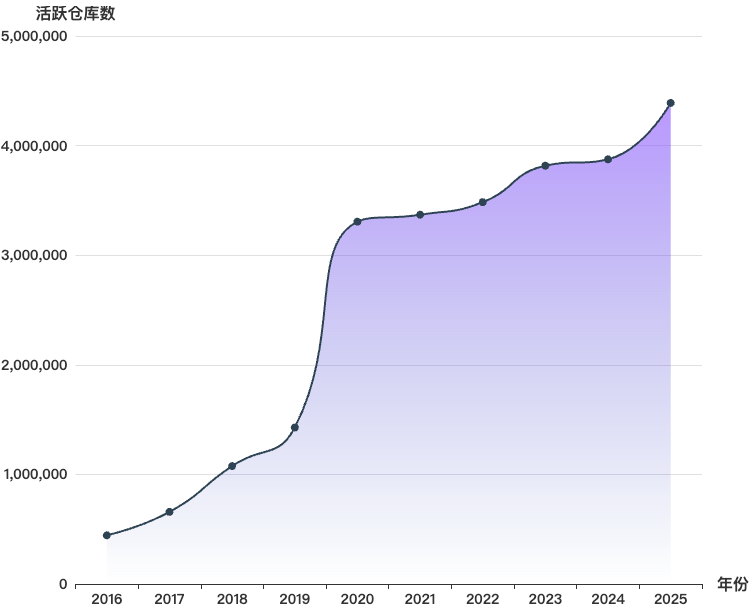
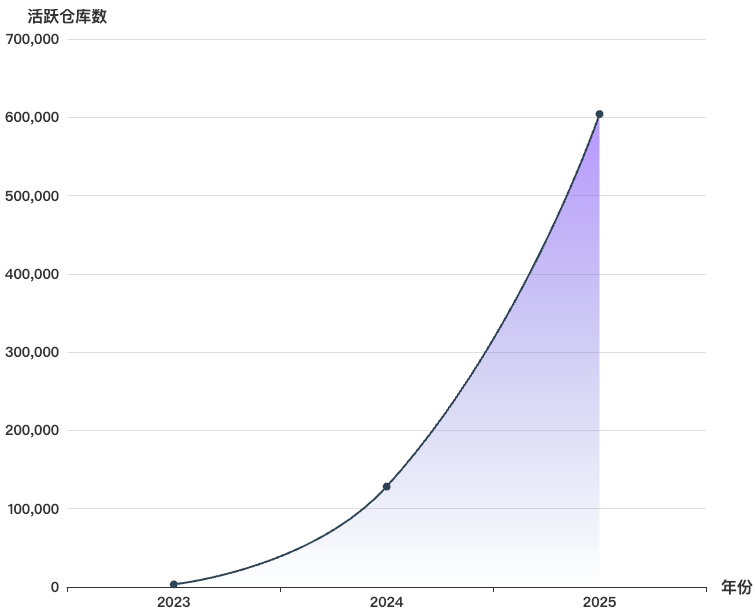
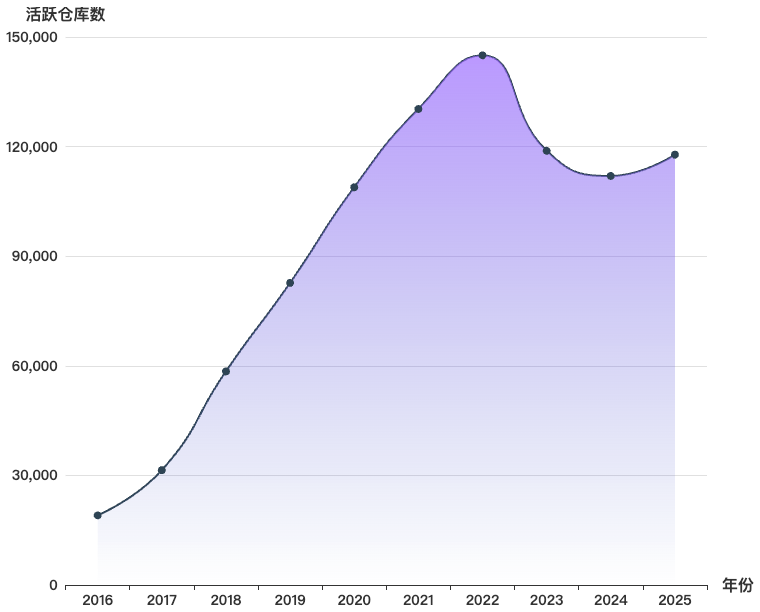
如上图所示,从 2016–2025 年活跃仓库数量变化来看,开源平台整体呈现出 规模持续扩大但增长节奏有所分化的趋势。全球开源项目数量总体保持增长态势,不同平台在发展阶段、增长速度以及波动程度上表现出差异。具体来看:
- GitHub 的活跃仓库数量整体保持稳定增长,从 223 万增长至 632 万,十年间增长约 183%。其中,2020—2021 年增长较为明显,这一阶段与疫情期间远程协作和线上开发活动增加有关,推动了开源项目数量的快速增长。尽管个别年份增速有所放缓,但总体仍呈现出成熟开源生态下的稳步扩张趋势。2025 年的增长尤为显著,凸显 AI 时代下活跃仓库加速涌现的趋势,也折射出 AI 技术推动创新正从“精英驱动”向“群体共创”深刻演进。
- Gitee 在早期阶段增长迅速,活跃仓库数从 44.5 万快速增长至 2020 年的 330.6 万,2021 年进一步增长至 336.9 万,并在 2021—2022 年间持续攀升至 348.4 万,同样与疫情期间远程开发和线上协作需求上升有关。此后平台规模持续稳步增长,2023 年达 381.7 万、2024 年达 387.5 万,并在 2025 年达到约 438.9 万的阶段性高点,显示出平台在经历快速扩张后仍保持持续增长态势。
- AtomGit/GitCode 于 2023 年 9 月启动,目前仅有三年数据,但增长速度显著,2025 年增长至超过 60 万,呈现出新兴开源平台在早期阶段的快速扩张特征。
- GitLab 平台活跃仓库数量在 2016—2022 年持续增长并于 2022 年达到高点,之后在 2023—2024 年有所回落,2025 年出现小幅回升,说明平台仓库活跃度整体由高速扩张逐步转向阶段性调整。
四大平台在活跃仓库规模上形成明显梯度:GitHub 处于成熟稳定增长阶段,Gitee 处于持续稳健增长、生态逐步成熟阶段,AtomGit/GitCode 则处于早期快速发展阶段,GitLab 整体由高速扩张逐步转向阶段性调整。
- AI 大模型成为最大增长极,引爆技术革命:AI 大模型相关仓库年均增长率超 210%,2024 年起跃居所有技术领域首位。Qwen(通义千问)、Llama、DeepSeek 等开源模型迅速获得百万级星标,推动“模型即服务”成为新范式,显著降低 AI 应用门槛。
- 高速成长领域多元并进,生态韧性增强:云基础设施(Kubernetes、Terraform)持续高活跃,支撑企业数字化转型;前端交互框架(React、Vue)与新兴编程语言(Rust、Go)因开发效率与安全性优势广受青睐;RISC-V 等硬件开源项目增速显著,被视为“后摩尔时代”的关键技术路径。
- 基础软件稳步演进,筑牢数字底座:数据库(PostgreSQL、OceanBase)、操作系统(Linux、OpenEuler)、大数据(Spark、Flink)、物联网(EdgeX)等领域保持稳定增长,构成坚实的技术基础设施。
- 中美技术话语权呈现结构性分化:美国在 AI 框架(PyTorch)、云原生(Kubernetes)、编译器等底层领域仍占主导;中国在 AI 大模型(Qwen、ChatGLM)、操作系统(OpenEuler)、分布式数据库(OceanBase)等方向快速追赶,部分领域实现并跑甚至局部领跑。
趋势总结:全球开源技术格局正从“单点突破”转向“多赛道协同演进”,AI 引领、云基支撑、根技术筑底的新生态日益成型。然而,技术标准碎片化、生态互操作性不足等风险,可能阻碍创新效率,需警惕“新巴尔干化”倾向。
为便于直观比较不同技术领域在总体影响力、项目规模及平均项目影响力三个维度的表现,采用散点气泡图进行可视化呈现(气泡大小与总体影响力正相关):
由图 2.3.3 可得出以下关键洞察:
- AI 与大模型在总体影响力和项目规模上均领先,是当前最具影响力的技术领域。
- 大数据与数据工程、物联网与边缘计算的平均项目影响力突出,位列前两位。
- 工业软件项目规模最小,但平均影响力较高。
- 技术领域可分为 "大规模 - 中影响力"(如前端)和 "小规模 - 高影响力"(如大数据)两类明显特征。
- 总体影响力与项目规模呈正相关趋势,但平均影响力分布相对独立。
2.4 开源人才地图
2.4.1 开篇定位:人才是开源生态的核心驱动力
全球开源人才地图(Global Open Source eXpertise Map, X-Map)旨在识别和刻画高影响力开发者在全球的分布格局,反映各国在开源核心人才储备与技术领导力方面的演进路径。
本小节采用 OpenRank 影响力(OpenRank Influence)作为核心指标,聚焦 OpenRank ≥ 200 的高影响力开发者群体,通过分析其地理归属与技术领域分布,揭示国家在高端数字人才集聚与创新能力上的战略竞争力。该指标超越简单的人才数量统计,真实反映开发者在协作网络中的技术话语权与社区领导力。
2.4.2 核心发现:美中双核驱动,全球人才格局进入“多极并进”新阶段
本报告以 OpenRank > 200 为门槛定义“高影响力开发者”(High-Impact Contributors),对 2016–2025 年全球主要国家该群体数量进行追踪分析,得出以下三大趋势。
- 美国持续领跑,十年翻倍增长:美国高影响力开发者从 2016 年的 248 人 增长至 2025 年的 398 人,稳居全球第一。其主导地位源于深厚的学术积累、活跃的企业生态(如 Google、Meta、Microsoft)、以及成熟的开源基金会体系(如 Linux Foundation、Apache Software Foundation),持续塑造全球技术标准与社区话语权。
- 中国实现跨越式跃升,跻身第二梯队:如图 2.13 所示,中国高影响力开发者从 2016 年仅 11 人 飙升至 2025 年 110 人,十年增长 10 倍,增速位居全球前列。这一突破得益于国家“科技自立自强”战略推动下,企业(华为、阿里、腾讯、字节跳动等)加大开源投入、高校科研成果转化机制完善,以及 Gitee、OpenAtom 等本土平台对高质量贡献者的激励与培育。
- 欧洲呈现多极稳定格局,协同效应凸显:德国(159 人)、英国(79 人)、法国(53 人)、加拿大(53 人)等国稳步发展,形成“欧洲四强”格局。德国凭借其工业软件与嵌入式系统优势,在 Automotive、IoT 领域贡献突出;英国依托剑桥、牛津等顶尖学府,在 AI 与云计算方向表现强劲;加拿大则在开源治理与安全领域具备较强影响力。
2.4.3 全球格局:美中引领,多国并进,未来竞争重心转向“人才质量”
当前全球开源人才分布呈现出 “美中引领、多国并进” 的多极格局:
表 2.6 2025 各国高影响力开发者数量及增速
| 国家 | 2025 高影响力开发者数 | 增速(2016–2025) |
|---|---|---|
| 美国 | 398 | +60% |
| 中国 | 110 | +900% |
| 德国 | 159 | +178% |
| 英国 | 79 | +88% |
| 法国 | 53 | +89% |
| 加拿大 | 53 | +29% |
- 全球高影响力开发者分布呈梯度格局,美国以 398 人的规模延续“全球领导力中心”定位,中国则以 900%的增速实现快速追赶,二者构成第一、第二梯队核心。
- 欧洲国家中,德国以 159 人的规模和 178%的增速,凸显“工业软件枢纽”优势,英法两国亦依托战略定位实现 1 倍左右增速,形成区域协同发展态势。
- 各国高影响力开发者的数量与增速,与“全球领导力”“工业枢纽”等战略定位高度契合,反映出战略导向对技术人才集聚的驱动作用。
三、开源影响力排行榜
从生态位到影响力:构建开源世界的“统一标尺”
在当今数字化时代,开源已超越代码共享的原始形态,演变为支撑全球数字文明的关键基础设施。衡量谁在真正塑造技术未来、谁在推动协作公平、谁在赋能边缘群体,不能仅依赖 Star 数或提交量等表层指标,而需一套兼具科学性、包容性与前瞻性的影响力评估体系。
本报告全面采纳 OSDGs(开源发展目标)框架,并依托 OpenRank 北极星指标,构建了覆盖“行为—质量—影响力”三层逻辑的全球可比排行榜体系。本章发布的四大权威榜单——行政区划、企业、成熟项目与新势力项目影响力排行榜——不仅反映中国开源力量在全球生态中的真实位势,更揭示区域协同、企业战略、技术创新与青年活力的深层图景。
榜单的时间窗口为 2025 年 1 月 1 日至 2025 年 12 月 31 日,并通过 OpenDigger 平台的多维标签体系(涵盖 34 个省级行政区、1,000+ 企业、200+ 技术领域)实现精准穿透分析。我们期望,这些排行榜不仅能树立标杆、引导方向,更能服务于国家数字战略、区域协调发展、企业开源治理与青年人才培养,真正将开源从“技术现象”升维为“社会价值创造机制”。
3.1 行政区划影响力排行榜
开源不仅是技术创新的引擎,更是区域数字经济竞争力的重要体现。在“东数西算”“全国统一大市场”等国家战略背景下,各省市如何通过开源构建本地技术生态、吸引高端人才、培育新质生产力,成为衡量区域高质量发展的重要维度。
本节基于全域 OpenRank 指标,综合评估中国 34 个省级行政区(含港澳台)在全球开源协作网络中的综合影响力。榜单不仅反映开发者数量与活跃度,更强调贡献质量、项目主导力与跨区域协作能力,有效避免“唯数量论”的偏差。通过该排行榜,我们可识别出如北京、上海、深圳等传统创新高地之外的“潜力型”区域(如成都、西安、合肥),并为中西部地区制定差异化开源扶持政策提供数据支撑,助力实现“数字中国”建设中的区域协调与共同繁荣。
3.1.1 全球行政区划影响力 Top 15:美国仍居主导,新兴市场加速追赶
在全球层面,加利福尼亚州以高达 5,574.8 的 OpenRank 值稳居榜首,遥遥领先于其他地区。其优势不仅源于硅谷聚集的科技巨头(如 Apple、Google、Meta),更在于其深厚的高校科研基础(斯坦福、伯克利)、完善的创业生态与开放的协作文化。加州是全球开源创新的“心脏地带”,其影响力远超单纯的人口或 GDP 数字。
表 3.1 全球行政区划影响力 Top 15
| # | 行政区划 | OpenRank | 开发者数量(万) | 所属国家 |
|---|---|---|---|---|
| 1 | 加利福尼亚州 | 5,574.8 | 593.96 | 美国 |
| 2 | 英格兰 | 4,348.45 | 410.29 | 英国 |
| 3 | 纽约州 | 2,521.37 | 275.68 | 美国 |
| 4 | 华盛顿州 | 2,037.95 | 185.97 | 美国 |
| 5 | 圣保罗 | 1,989.35 | 229.73 | 巴西 |
| 6 | 安大略省 | 1,844.54 | 162.63 | 加拿大 |
| 7 | 柏林市 | 1,628.85 | 115.85 | 德国 |
| 8 | 得克萨斯州 | 1,610.33 | 206.56 | 美国 |
| 9 | 法兰西岛 | 1,527.02 | 147.69 | 法国 |
| 10 | 首尔特别市 | 1,465.92 | 187.52 | 韩国 |
| 11 | 东京都 | 1,279.69 | 274.06 | 日本 |
| 12 | 北京市 | 1,248.72 | 332.19 | 中国 |
| 13 | 马萨诸塞州 | 1,232.39 | 116.21 | 美国 |
| 14 | 巴伐利亚州 | 1,083.71 | 79.08 | 德国 |
| 15 | 上海市 | 1,060.37 | 244.05 | 中国 |
紧随其后的是英格兰(4,348.45),反映出英国在人工智能、金融科技与软件工程领域的持续投入。尽管伦敦以外地区尚未形成同等规模的集群效应,但牛津、剑桥等高校驱动的开源社区正在崛起。
纽约州(2,521.37)位列第三,其影响力主要来自曼哈顿的金融科技创新与长岛的科研机构。值得注意的是,华盛顿州(2,037.95)虽未进入前三,但其在云计算(Azure、AWS)、AI 工具链(GitHub)方面的贡献使其成为美国西部的另一极。
巴西的圣保罗(1,989.35)和加拿大的安大略省(1,844.54)分别位居第五与第六,显示出拉美与北美在开源生态中的差异化路径。圣保罗依托其庞大的工程师群体与制造业转型需求,在嵌入式系统与工业软件领域表现突出;而安大略则凭借多伦多大学、滑铁卢大学等学术资源,在 AI 与区块链方向形成独特优势。
德国的柏林市(1,628.85)与法国的法兰西岛(1,527.02)分列第七与第九,表明欧洲在开源治理、标准共建与绿色计算方面仍具引领作用。韩国的首尔特别市(1,465.92)与日本的东京都(1,279.69)也进入前十,反映出东亚在移动互联网、智能制造与基础软件领域的深厚积累。
值得关注的是,北京市(1,248.72)与上海市(1,060.37)分别位列第十二与第十五,成为全球前二十中仅有的两个中国城市。这表明中国已具备与世界先进水平竞争的开源能力,尤其在北京、上海两大国际科创中心,形成了“政府引导 + 企业主导 + 高校协同”的高效模式。
3.1.2 全球开源生态的地理分布格局:谁在主导协作网络?
在全球行政区划开发者 OpenRank 排行榜(Top 100)中,不仅能看到领先区域的技术实力,更能洞察各国在全球开源协作网络中的参与广度与组织能力。一个国家若有多地同时进入百强,往往意味着其已形成多层次、多中心的开源创新集群,具备更强的生态韧性与人才吸附力。
为更清晰地呈现这一格局,我们对 Top 100 榜单中各国家的入选行政区数量进行了统计,并按数量从高到低排序如下:
表 3.2 全球行政区划影响力 Top 100 各国入选数量
| 排名 | 国家 | 入选数量 |
|---|---|---|
| 1 | 美国 | 23 |
| 2 | 德国 | 10 |
| 3 | 中国 | 8 |
| 3 | 巴西 | 8 |
| 5 | 加拿大 | 5 |
| 5 | 印度 | 5 |
| 7 | 西班牙 | 3 |
| 7 | 法国 | 3 |
| 7 | 澳大利亚 | 3 |
| 10 | 英国、韩国、越南、俄罗斯、荷兰 | 2 |
| 15 | 阿根廷、比利时、哥伦比亚、捷克、芬兰、印度尼西亚、爱尔兰、意大利、日本、肯尼亚、挪威、巴基斯坦、葡萄牙、斯里兰卡、瑞典、瑞士、土耳其、乌克兰 | 1 |
分析与洞察:多极化趋势显现,但头部集中效应依然显著:
从入选数量来看,美国以 23 席遥遥领先,覆盖从加州、纽约到德州、华盛顿州等几乎所有科技重镇,充分体现了其作为全球开源“核心枢纽”的地位。无论是企业主导(如微软、Google)、高校驱动(如 MIT、Stanford),还是社区自发协作,美国已构建起高度成熟且多元化的开源生态体系。
紧随其后的是德国(10 席),作为欧洲开源高地,其优势不仅体现在柏林、慕尼黑等大城市,更延伸至巴伐利亚、北威州、巴符州等多个联邦州,反映出德国在工业软件、嵌入式系统、操作系统等基础领域的深厚积累和广泛动员能力。
值得关注的是,巴西与中国并列第三(各 8 席),展现出新兴经济体的强劲崛起势头。
- 巴西的圣保罗、里约热内卢、米纳斯吉拉斯等地持续输出高质量贡献,尤其在 Web 开发、教育工具和本地化基础设施方面表现活跃;
- 中国则依托北京、上海、广东、浙江、江苏、四川等省市,形成了“东中西部协同、产学研联动”的开源发展格局,特别是在操作系统、AI 框架、数据库等战略领域实现系统性突破。
此外,加拿大、印度、西班牙、法国、澳大利亚等国均有多地入围,显示出全球开源生态正从“单极主导”向“多极共生”演进。然而,榜单后半段大量国家仅有一地入选,也说明大多数国家仍处于“点状突破”阶段,尚未形成区域性协同效应。
这一分布格局提醒我们:未来开源竞争力不仅取决于个别明星城市或企业的表现,更依赖于国家级开源基础设施的统筹布局、教育体系的深度融入,以及跨区域协作机制的制度化建设。唯有如此,才能在全球数字文明进程中占据主动。
3.1.3 中国行政区划影响力 Top 15:双核引领,多点开花
在中国内部排行榜中,开源生态呈现出“双核驱动、梯度扩散、区域协同”的格局。
表 3.3 中国行政区划影响力 Top 15
| # | 行政区划 | OpenRank | 开发者数量(万) |
|---|---|---|---|
| 1 | 北京市 | 12,487.72 | 332.19 |
| 2 | 上海市 | 10,601.37 | 244.05 |
| 3 | 广东省 | 7,768.99 | 215.43 |
| 4 | 台湾省 | 7,200.46 | 137.85 |
| 5 | 浙江省 | 6,045.81 | 130.53 |
| 6 | 江苏省 | 2,886.68 | 81.51 |
| 7 | 四川省 | 2,795.84 | 70.03 |
| 8 | 湖北省 | 1,839.26 | 49.25 |
| 9 | 陕西省 | 1,153.73 | 33.14 |
| 10 | 福建省 | 934.61 | 24.34 |
| 11 | 山东省 | 826.96 | 23.2 |
| 12 | 湖南省 | 811.66 | 20.86 |
| 13 | 重庆市 | 696.07 | 19.03 |
| 14 | 安徽省 | 688.02 | 18.9 |
| 15 | 辽宁省 | 504.79 | 16.58 |
北京市以 12,487.72 的 OpenRank 值高居榜首,开发者数量达 332.19 万人,是全国唯一的“超大型开源枢纽”。其优势集中体现在:
- 头部企业密集:华为、百度、小米、字节跳动等科技巨头总部设于北京;
- 高校科研强:清华、北大、北航、中科院等机构持续输出原创性研究成果;
- 政策支持有力:海淀、昌平等地设立多个开源产业园与创新基金。
上海市以 10,601.37 的 OpenRank 居第二,开发者数量 244.05 万人,仅次于北京。其特点在于:
- 国际化程度高:外资企业与跨国公司云集,推动开源标准对接;
- 金融与人工智能融合:在 AI 金融、智能投顾、区块链等领域形成特色生态;
- 长三角协同效应显著:与杭州、苏州、南京等地形成“研发-应用-服务”闭环。
广东省以 7,768.99 的 OpenRank 位列第三,开发者数量 215.43 万人,是全国唯一一个省级单位进入 Top3 的省份。其影响力主要由 深圳市(4,440.85 OpenRank)驱动,作为中国最具活力的科技创新城市,深圳在硬件开源(如 RISC-V、物联网)、AI 芯片、机器人等领域持续突破。
台湾省以 7,200.46 的 OpenRank 位居第四,开发者数量 137.85 万人,显示出其在半导体设计、嵌入式系统与软件工具链方面的深厚积累。台北市作为核心节点,拥有大量从事芯片验证、EDA 工具开发的工程师团队。
浙江省(6,045.81)与江苏省(2,886.68)分列第五与第六,分别以杭州、苏州为核心,形成“数字经济”与“智能制造”双轮驱动的开源格局。杭州依托阿里巴巴、蚂蚁集团等企业,在云计算、数据库、AI 大模型方向持续发力;苏州则聚焦于工业互联网、智能制造与边缘计算。
此外,四川省(2,795.84)、湖北省(1,839.26)、陕西省(1,153.73)等中西部省份也展现出强劲增长势头。成都、武汉、西安凭借高校资源与产业政策,逐步形成“高校-企业-社区”联动的开源生态,成为未来潜在的增长极。
3.1.4 城市级深度洞察:谁是真正的“开源引擎”?
为进一步揭示中国开源生态的微观结构,我们对地级市进行了 OpenRank 分析。数据显示:
表 3.4 中国城市级影响力 Top 15
| 地级市 | 所属省份 | OpenRank 总和 | 开发者数量(万) | 人均 OpenRank(万人) | 上榜代表企业 |
|---|---|---|---|---|---|
| 北京市 | 直辖市 | 11,961.74 | 332.19 | 36.00872994 | ByteDance、Baidu |
| 上海市 | 直辖市 | 10,184.38 | 244.05 | 41.73071092 | ESPRESSIF、DaoCloud |
| 杭州市 | 浙江省 | 5,539.76 | 78.66 | 70.42664633 | Alibaba、Ant Group |
| 深圳市 | 广东省 | 4,440.85 | 78.02 | 56.91937965 | Huawei、Tencent |
| 台北市 | 台湾省 | 2,726 | 31.71 | 85.96657206 | - |
| 成都市 | 四川省 | 2,541.42 | 43.22 | 58.80194354 | - |
| 广州市 | 广东省 | 2,408.81 | 50.27 | 47.91744579 | DCloud、Vipshop |
| 武汉市 | 湖北省 | 1,693.07 | 30.46 | 55.58338805 | Deepin、Douyu |
| 南京市 | 江苏省 | 1,607.67 | 32.32 | 49.74226485 | - |
| 西安市 | 陕西省 | 1,061.61 | 20.88 | 50.8433908 | - |
| 苏州市 | 江苏省 | 754.69 | 12.6 | 59.89603175 | - |
| 长沙市 | 湖南省 | 590.25 | 10.75 | 54.90697674 | - |
| 重庆市 | 重庆市 | 567.11 | 9.87 | 57.45795339 | - |
| 合肥市 | 安徽省 | 554.26 | 9.91 | 55.92936428 | iFLYTEK |
| 厦门市 | 福建省 | 527.67 | 9.19 | 57.41784548 | - |
可以看出,北京、上海、杭州、深圳、台北、成都、广州是中国开源生态的“七大城市引擎”。其中:
- 北京稳居“双料冠军”,上海紧随其后:北京市以 332.19 万活跃开发者和 11,961.74 的 OpenRank 总值,双双位居全国第一,持续发挥国家科技创新中心的引领作用。上海市则以 244.05 万开发者和 10,184.38 的 OpenRank 总值排名第二,展现出强劲的综合创新实力。两城合计贡献了全国近 40% 的开源影响力,构成中国开源生态的“双核引擎”。
- 杭州稳居大陆人均榜首,彰显高质量创新生态:杭州市以 78.66 万开发者实现人均 OpenRank 70.43,为中国大陆最高。这得益于阿里巴巴与蚂蚁集团构建的“生产级开源范式”——从 Dubbo、RocketMQ 到 Seata、Apache Flink(深度贡献)、Tongyi Qianwen 系列模型,其开源项目不仅数量多,更强调工业落地性、文档完备性与社区运营成熟度,极大提升了单位开发者的影响力产出效率。
- 深圳、成都、苏州等地紧随其后,展现多元路径:深圳(56.92)依托华为、腾讯的全栈技术输出;成都(58.80)凭借 DataCanvas 等 AI 原生企业实现高效转化;苏州(59.90)虽无头部上榜企业,但依托长三角制造业基础,在工业软件、边缘计算等垂直领域形成高价值贡献,人均效率甚至超过广州、南京。
- 台北人均效率全国第一:台北市以仅 31.71 万开发者,实现人均 OpenRank 高达 85.97,位居全国首位。这一高效率源于其在半导体设计、嵌入式系统、开源硬件和 EDA 工具链等领域的深厚积累。尽管榜单中无企业直接标注“台北”,但大量台湾科技人才通过全球协作(如参与 Linux 内核、Chisel、OpenTitan 等项目)贡献高质量代码,且本地企业(如联发科、华邦电子、晶心科技)长期深度参与国际开源生态,形成“小而精、高技术密度”的独特模式。
结合中国地级市 2025 年 OpenRank 热力图,我们可以观察到:
- 开源活动高度集中在东部沿海地区,尤其是京津冀、长三角、珠三角三大城市群;
- 中西部部分城市(如西安、合肥、长沙、重庆)形成“次级热点”,显示出区域协同发展的潜力;
- 新疆、西藏、青海等西部地区虽基数较低,但近年来增速较快,表明国家“数字丝绸之路”战略正在落地。
对比与洞察:中国如何在全球坐标系中定位?
将全球与中国榜单对比,可以发现以下关键趋势:
- 中国在“量”上接近世界前列,但在“质”上仍有差距。 北京、上海虽进入全球 Top 15,但 OpenRank 值仍远低于加州、英格兰,说明中国开发者整体贡献深度与国际话语权仍需提升。
- “双核驱动”是中国的独特优势。 北京与上海的协同效应,使得中国在基础研究与产业应用之间形成了良性循环,这是许多单一城市主导的国家难以复制的。
- 中西部城市正在形成“新势力”。 成都、西安、武汉、合肥等城市的 OpenRank 快速上升,表明中国正从“沿海依赖”向“内陆协同”转型,为区域协调发展提供了新路径。
- 开源已成为城市竞争力的新维度。 各地政府纷纷出台“开源专项政策”,如北京“开源创新行动计划”、上海“AI 开源生态建设指南”、深圳“RISC-V 开源基金”,标志着开源已从“技术选择”上升为“战略资产”。
3.2 开源企业影响力排行榜
企业是开源生态的核心参与者与重要推动力量。从早期“使用者”到如今的“共建者”乃至“引领者”,中国企业在开源领域的角色正在发生深刻转变。然而,真正的开源影响力并非来自简单地“开源一个项目”,而是体现在对关键基础设施的维护深度、社区治理的透明度、跨组织协作的开放度以及对全球标准的贡献度上。
本节发布 2025 年中国开源企业影响力排行榜,涵盖科技巨头(如华为、阿里、腾讯)、基础软件厂商(如 OceanBase、PolarDB)、AI 初创公司及非营利组织。榜单采用 社区 OpenRank 与全域 OpenRank 双重加权,重点考察企业在核心项目中的维护者角色、Pull Request 合并率、Issue 响应时效、文档国际化水平等质量维度。我们特别关注那些虽规模不大但深度参与国际主流项目(如 Kubernetes、Apache Flink)的“隐形冠军”,彰显中国企业在开源治理中的多元路径与真实贡献。
3.2.1 全球开源企业影响力 Top 15:中美双强格局持续深化
在 2025 年全球开源企业影响力排行榜中,Microsoft 以高达 205,596.64 的 OpenRank 值稳居榜首,连续多年保持领先地位。其优势不仅源于对 Azure、Visual Studio Code、.NET 等主流工具链的深度投入,更在于其在全球开发者社区中构建了强大的协作网络与信任机制;尽管其 OpenRank 较去年增长 47,395.82,但增速趋于平稳,反映出其作为“生态基石”的成熟状态。
表 3.5 全球开源企业影响力 Top 15
| # | 企业名称 | OpenRank(含同比变化) | 活跃仓库数 | 活跃开发者数 | 所属国家 |
|---|---|---|---|---|---|
| 1 | Microsoft | 205,596.64 (+47,395.82) | 5,782 | 116,881 | 美国 |
| 2 | Huawei | 89,368.78 (+12,607.45) | 8,273 | 12,716 | 中国 |
| 3 | 75,962.65 (−21,091.96) | 1,663 | 50,724 | 美国 | |
| 4 | Amazon | 49,969.58 (+10,234.11) | 3,527 | 24,170 | 美国 |
| 5 | Meta | 44,005.22 (+8,762.33) | 706 | 23,311 | 美国 |
| 6 | RedHat | 38,091.50 (+5,418.90) | 817 | 7,828 | 美国 |
| 7 | NVIDIA | 37,351.36 (+6,392.54) | 681 | 12,781 | 美国 |
| 8 | Elastic | 36,883.73 (+9,201.47) | 412 | 3,802 | 美国 |
| 9 | Grafana Labs | 30,430.93 (+7,845.22) | 522 | 8,009 | 美国 |
| 10 | Alibaba | 26,349.25 (−5,670.27) | 2,797 | 14,595 | 中国 |
| 11 | Mozilla | 25,539.37 (+3,102.84) | 672 | 11,857 | 美国 |
| 12 | Hugging Face | 23,794.95 (+5,212.82) | 221 | 13,575 | 美国 |
| 13 | DataDog | 20,850.26 (+4,337.61) | 427 | 4,550 | 美国 |
| 14 | IBM | 20,527.84 (−2,984.55) | 2,119 | 13,712 | 美国 |
| 15 | Nabu Casa Inc. | 19,967.42 (+18,421.03) | 67 | 23,622 | 美国 |
紧随其后的是华为,以 89,368.78 的得分位居第二,同比增长 12,607.45,展现出强劲的增长动能。华为在 OpenHarmony、昇腾 AI、KubeEdge 等项目的持续投入,使其成为少数能够同时影响基础软件、AI 芯片与物联网生态的中国企业代表。尤其值得注意的是,华为在非欧美主导的技术领域实现了显著突破,体现了其“自主可控 + 开放协同”的双重战略。
Google 位列第三,OpenRank 为 75,962.65,较上年下降 21,091.96,显示出其在部分核心项目(如 Android、TensorFlow)中面临社区分化与竞争加剧的压力。尽管如此,其在 AI 框架、云原生与开发者工具方面的长期积累仍维持着极高的影响力。
Amazon、Meta、RedHat 分列第四至第六位,分别依托 AWS、React、Kubernetes 等关键项目构筑生态壁垒。其中,NVIDIA 表现尤为亮眼,排名上升三位至第七,OpenRank 达 37,351.36,同比增长 6,392.54,这主要得益于其在 CUDA 生态、AI 训练框架(如 TensorRT)及 Hugging Face 合作项目中的深度参与,标志着硬件厂商正加速向“软件定义”转型。
值得关注的是,Hugging Face 首次进入全球 Top 15,排名第十二,OpenRank 为 23,794.95,同比增长 5,212.82。作为 AI 大模型时代的“新基础设施”,Hugging Face 在模型共享、推理部署与社区治理方面的创新,使其成为连接研究与产业的关键枢纽,也预示着开源模式正在从“代码共享”迈向“模型即服务”的新阶段。
此外,我们还追踪了 2016–2025 年间 Top 15 企业的 OpenRank 趋势,揭示开源影响力的动态演化规律:
核心发现:
- NVIDIA 实现历史性突破,从边缘走向中心: NVIDIA 在 2024 年首次进入全球 Top 15,位列第 10 名;到 2025 年已跃升至第 7 名,成为近年来增长最迅猛的科技巨头之一。这一跃迁的背后,是其在 GPU 架构、CUDA 生态、大模型推理优化工具(如 TensorRT-LLM) 等领域的系统性开源布局。尤其值得注意的是,NVIDIA 并非传统意义上的“软件公司”,而是通过将硬件能力与开源软件深度绑定,构建起“算力 + 框架 + 社区”的三位一体生态,成功实现了从“芯片供应商”向“AI 基础设施平台”的战略转型。
- Hugging Face 成为 AI 开源新引擎,稳居头部阵营: Hugging Face 于 2023 年首次进入 Top 15,排名第 14;2024 年上升至第 12 名,并在 2025 年保持稳定,继续位居第 12。作为全球最大的开源模型社区,其核心价值在于将“预训练模型”转化为可复用、可部署的标准化资产。通过 Model Hub、Inference API 和 Transformers 库等工具,Hugging Face 极大地降低了大模型的使用门槛,推动了 AI 技术的民主化。其连续三年稳定在 Top 15,标志着“模型即服务”(MaaS)模式已成为全球开发者不可或缺的基础设施。
- Mozilla 逐步退出主流竞争,开源战略面临重构: Mozilla 曾是全球开源生态的重要力量——2016 年位列第 5,2017 年升至第 4,一度被视为“浏览器革命”的象征。然而自 2018 年起,其排名持续下滑,2024 年和 2025 年均稳定在第 11 名,反映出其在移动互联网、AI 驱动的新场景中未能及时调整战略。尽管 Firefox 浏览器仍具影响力,但其在 AI、云原生、开发者工具等新兴领域缺乏具有广泛影响力的开源项目输出,导致社区活跃度下降,逐渐被边缘化。
- 中国力量实现历史性突破: 华为自 2021 年起排名持续攀升,2023 年跃居第 3,2024 年稳居第 2,2025 年维持第 2,成为唯一进入全球前五的非美国企业。其在 OpenHarmony、MindSpore、昇腾 AI 芯片等领域的系统性开源投入,正在构建一条独立于西方的技术路径,展现了中国企业在开源战略上的长期主义与全局视野。
同时,本小节还给出了 2025 年内的全球企开源影响力变化图,如下图所示。
核心发现:
- NVIDIA 实现“火箭式”增长:NVIDIA 在 2025 年表现出惊人的上升势头——从年初第 9 名一路攀升至年末第 4 名,并在 10 月一度超越 Amazon 和 Meta。这一跃升得益于其在 CUDA 生态、AI 推理优化工具(如 TensorRT-LLM)、大模型训练框架(如 NVFuser) 等方向的系统性开源布局,成功将硬件优势转化为软件生态竞争力。
- Elastic 逆势突围,重回前列:Elastic 在 2025 年初排名徘徊于第 7~8 名,但自 6 月起凭借 OpenSearch 的持续迭代 与 可观测性工具链(如 Elastic Observability) 的社区活跃度提升,实现反超,最终以第 6 名收尾,表明传统企业级软件厂商仍具备强大的技术反弹能力。
- 新兴力量加速崛起,行业格局持续重构:Mozilla、Alibaba 和 DataDog 等企业在今年内多次出现排名波动,展现出强劲的开源投入与生态影响力。尤为值得关注的是,Tenstorrent 于 2025 年 10 月首次进入全球开源影响力前 15 名,并在随后两个月中稳步上升至第 12 位,显示出其在 AI 基础设施领域的快速扩张与社区认可度提升。与此同时,Ant Group 和 Zed Industry 也在 2025 年 11 月相继跻身前 15 行列,标志着中国科技企业及新兴技术公司在开源生态中的参与度显著增强。这一系列动态表明,传统巨头主导的格局正在被多元化的创新主体打破,全球开源竞争正进入一个更加开放、活跃且充满变数的新阶段。
3.2.2 中国开源企业影响力 Top 15:头部领先,新势力崛起
在中国市场,开源已从“技术补充”升级为“战略必需”。2025 年中国开源企业影响力排行榜呈现出“头部稳固、梯队清晰、新星涌现”的特点。
表 3.6 中国开源企业影响力 Top 15
| # | 企业名称 | OpenRank(含同比变化) | 活跃仓库数 | 活跃开发者数 | 所属国家 |
|---|---|---|---|---|---|
| 1 | Huawei | 89,368.78 (+12,607.45) | 8,273 | 12,716 | 中国 |
| 2 | Alibaba | 26,349.25 (−5,670.27) | 2,797 | 14,595 | 中国 |
| 3 | Ant group | 18,679.05 (+4,002.61) | 768 | 10,726 | 中国 |
| 4 | ByteDance | 16,625.76 (+6,703.16) | 458 | 12,398 | 中国 |
| 5 | Baidu | 13,651.87 (−5,339.68) | 152 | 5,841 | 中国 |
| 6 | PingCAP | 7,917.36 (+1,878.88) | 99 | 845 | 中国 |
| 7 | ESPRESSIF | 6,141.94 (+1,226.29) | 171 | 4,293 | 中国 |
| 8 | Tencent | 5,717.46 (+1,492.99) | 254 | 4,629 | 中国 |
| 9 | Fit2Cloud | 4,945.60 (+2,065.73) | 65 | 2,562 | 中国 |
| 10 | DaoCloud | 4,558.18 (−8,306.29) | 61 | 1,929 | 中国 |
| 11 | SelectDB | 4,099.92 (+873.02) | 11 | 756 | 中国 |
| 12 | LobeHub | 4,037.59 (+231.96) | 26 | 1,865 | 中国 |
| 13 | Zilliz | 3,561.51 (−431.39) | 55 | 1,502 | 中国 |
| 14 | openKylin | 3,180.90 (−922.31) | 1,283 | 773 | 中国 |
| 15 | StarRocks | 2,770.29 (−762.91) | 19 | 762 | 中国 |
华为以绝对优势蝉联第一,OpenRank 达 89,368.78,远超第二名阿里巴巴(26,349.25),彰显其在操作系统、通信协议、芯片架构等底层技术领域的系统性布局。华为不仅是国内开源的最大贡献者之一,更是推动国产替代与国际标准共建的重要力量。
阿里巴巴位居第二,其在数据库(OceanBase、PolarDB)、云计算(Aliyun)、中间件(RocketMQ)等方向的持续投入,使其成为数字经济基础设施的“稳定器”。尽管 OpenRank 同比下降 5,670.27,但其在 AI Agent、大模型推理优化等新兴领域的布局正在蓄势待发。
蚂蚁集团(Ant Group) 以 18,679.05 的得分位列第三,同比增长 4,002.61,反映出其在区块链(Hyperledger Fabric)、金融级分布式系统(SOFAStack)及隐私计算等领域的深耕成果。其开源策略更加注重合规性与安全性,契合金融行业的特殊需求。
字节跳动(ByteDance) 名次大幅提升,跃升两位至第四,OpenRank 为 16,625.76,同比大幅增长 6,703.16。这主要得益于其在视频处理、推荐算法、AIGC 工具链(如 PicoX、TikTok SDK)等方面的开源尝试,逐步从“应用层创新”向“技术底座输出”转型。
百度位列第五,OpenRank 为 13,651.87,同比下降 5,339.68,反映出其在 AI 框架(PaddlePaddle)推广过程中面临的挑战。尽管技术实力雄厚,但在社区运营与生态整合方面仍有提升空间。
令人振奋的是,一批专注于垂直领域的“新势力”企业开始崭露头角:
- PingCAP(第 6)凭借 TiDB 在云原生数据库领域的持续突破,OpenRank 同比增长 1,878.88;
- ESPRESSIF(乐鑫)(第 7)在 RISC-V 物联网芯片与嵌入式开发工具链上的开源实践,助力中国在硬件层面实现自主可控;
- LobeHub(第 12)作为 AI 可视化训练平台的代表,其 OpenRank 上涨 231.96,体现了“低代码+AI”模式在开发者群体中的快速普及;
- Zilliz(第 13)则在向量数据库(Milvus)领域持续发力,推动 AI 应用落地。
此外,DaoCloud、openKylin 等企业在容器化、操作系统国产化方面的贡献虽未进入前十,但其在特定场景下的影响力不容忽视。
下图则是通过追踪 2016–2025 年间中国 Top 15 企业的 OpenRank 轨迹,揭示开源影响力的动态演化规律。
从 2016—2025 年中国科技企业开源影响力十年跃迁变化来看,呈现出头部企业格局动态调整、新兴企业快速崛起且不同领域企业发展节奏分化的特征:
- 华为强势领跑:从 2016 年第 15 名一路跃升,2022 年起稳居全球第 2,成为中国唯一进入全球前二的非美企业。其在 OpenHarmony、MindSpore 和昇腾生态的系统性开源布局,构建了全栈自主技术体系。
- 字节跳动快速崛起:2021 年首次入榜,2025 年已升至第 4 名,凭借 RAGFlow、verl 等 AI 工具链项目,完成从内容平台向技术公司的转型。
- 腾讯稳步回升,百度波动下行:腾讯依托云开放生态,2025 年稳定在第 8 名;百度受 PaddlePaddle 活跃度下滑影响,排名从早期 第 2 降至第 5。
- 垂直领域新锐涌现:PingCAP(TiDB)、ESPRESSIF(ESP32)、LobeHub(AI 可视化建模)和 StarRocks 等企业凭借细分技术优势,持续进入 Top 15。
- 部分企业显著退坡:
- DaoCloud 从 2024 年 Top 5 跌至 2025 年第 10 名,主因社区投入减弱、缺乏 AI 原生项目;
- StarRocks 作为全球最快的开源湖仓查询引擎(Linux Foundation 项目),在 2024 与 2025 年连续两年滑落至第 15 名。推测可能是因为 StarRocks 背后的公司(原 SelectDB,现 StarRocks Inc.)在 2023–2024 年加速商业化进程,将更多高级功能(如向量化优化、湖仓联邦查询增强)纳入企业版或云服务中,导致核心开源版本的功能迭代节奏减缓,削弱了对社区开发者的吸引力。
同时,本小节还给出了 2025 年内中国头部企业的开源影响力变化图,如下图所示:
核心发现:
- 字节跳动强势崛起,实现“弯道超车”:ByteDance 在 2025 年初排名第 4,但自 5 月起快速上升,于 7 月超越 Baidu 和 Ant Group,最终以第 3 名收尾。其增长动力主要来自 Rust 编程语言工具链、AI 编程助手、大模型推理优化框架 等项目的开源贡献,标志着其从“内容平台”向“技术驱动型公司”的战略转型取得实质性突破。
- DaoCloud 断崖式下滑,暴露生态可持续性挑战: DaoCloud 是本年度最值得关注的退坡案例——其 OpenRank 从年初的第 6 名一路下滑,至年末跌至第 15 名,跌幅超过 60%。这一剧烈下滑反映出其在 2025 年未能维持有效的社区运营与项目迭代:一方面,其核心产品 DaoCloud Enterprise 的开源版本更新频率显著降低;另一方面,在 AI 原生基础设施(如模型部署、推理调度)等热点方向缺乏具有影响力的新开源项目,导致开发者关注度快速流失。作为曾代表中国云原生先锋力量的企业,DaoCloud 的退步警示我们:开源影响力不仅依赖初期技术领先,更需要长期、稳定、面向开发者的生态投入。
- 新兴力量加速洗牌,垂直领域竞争白热化:
- PingCAP 与 ESPRESSIF 均在年内多次实现排名互换,前者凭借 TiDB 的全球化推广与社区运营能力稳居 Top 10,后者则因 ESP32 系列芯片的开源固件生态持续扩张而获得关注。
- LobeHub 作为 AI 可视化建模平台,在 10 月后迅速上升,成为少数能冲击 Top 10 的初创企业代表,体现了“低代码 + AI”模式在开发者中的吸引力。
- StarRocks 与 Zilliz 同样表现亮眼,分别在数据库与向量检索领域构建了强大的技术壁垒,成为国产替代的重要力量。
- 开源生态进入“多极化”时代:2025 年的中国开源格局呈现出“头部稳定、腰部活跃、尾部爆发”的特征。华为与阿里构成第一梯队,字节跳动、腾讯、PingCAP 形成第二梯队,而 LobeHub、Zilliz、DaoCloud 等企业在特定领域快速崛起,共同推动中国开源生态从“模仿跟随”走向“原创引领”。
3.3 开源项目影响力排行榜
一个开源项目的真正价值,不在于其是否“火爆”,而在于它是否成为技术生态的基石、开发者协作的枢纽、产业落地的桥梁。2025 年,全球范围内涌现出一批具有高度韧性的成熟项目,它们在基础软件、AI 框架、开发工具等领域持续演进,构建起复杂而稳定的协作网络。
我们不仅关注项目的代码规模,更重视其对 OSDGs 三大支柱(环境、社会、治理)的贡献——例如是否支持绿色计算、是否促进教育普惠、是否建立透明的治理机制。这些项目不仅是技术创新的载体,更是数字文明共建的公共基础设施。
3.3.1 全球开源项目影响力 Top 15:中国开源力量强势崛起,基础软件与 AI 双轮驱动
根据最新的全球开源项目排行榜数据,全球开源生态格局迎来了历史性重塑。本期榜单最显著的特征是中国主导的基础软件项目实现断层式领先,同时微软等科技巨头的项目群依然保持强劲势头,而 AI 大模型推理等新兴方向也加速渗透至核心梯队。以下是全球影响力排名前 15 的开源项目详细数据:
表 3.7 全球开源项目影响力 Top 15
| 排名 | 项目名称 | OpenRank | 开发者规模 | 发起组织 | 所在国家 |
|---|---|---|---|---|---|
| 1 | OpenHarmony | 60,089.18 | 6,487 | OpenAtom Foundation | 中国 |
| 2 | Azure | 40,923.04 | 16,128 | Microsoft | 美国 |
| 3 | NixOS | 26,457.31 | 9,521 | Stichting NixOS Foundation | 荷兰 |
| 4 | C#/.Net | 26,444.52 | 14,266 | Microsoft | 美国 |
| 5 | LLVM | 24,931.93 | 5,998 | University of Illinois Urbana-Champaign | 美国 |
| 6 | DataDog | 20,850.26 | 4,550 | DataDog | 美国 |
| 7 | OpenShift | 20,670.92 | 2,429 | RedHat | 美国 |
| 8 | VSCode | 20,589.02 | 35,458 | Microsoft | 美国 |
| 9 | Home Assistant | 19,967.42 | 23,622 | Nabu Casa Inc. | 美国 |
| 10 | openEuler | 16,257.57 | 3,285 | OpenAtom Foundation | 中国 |
| 11 | Odoo | 14,422.54 | 2,296 | Odoo | 比利时 |
| 12 | vLLM | 12,862.73 | 10,254 | - | - |
| 13 | Rust | 12,626.95 | 6,611 | Rust Foundation | 美国 |
| 14 | Swift | 12,520.10 | 1,595 | Apple | 美国 |
| 15 | Conda Forge | 11,431.75 | 4,402 | - | - |
榜单关键性洞察:
首先,中国开源力量实现了里程碑式的突破。由开放原子开源基金会发起的 OpenHarmony 以超过 6 万的 OpenRank 值高居榜首,其得分几乎是第二名 Azure 的 1.5 倍,显示出中国在万物互联操作系统领域的巨大投入与生态聚合能力。同时,openEuler 成功跻身前十,位列第 10,标志着中国在服务器操作系统领域也占据了重要一席。这两个项目的强势表现,彻底改变了以往由欧美项目垄断头部位置的局面。
其次,巨头生态的“集群效应”依然显著。美国微软公司表现尤为突出,旗下 Azure(第 2)、C#/.Net(第 4)、VSCode(第 8)三个项目同时进入前十,且 VSCode 拥有高达 3.5 万的开发者规模,位居所有项目之首,证明了其在开发者工具链和云基础设施上的绝对统治力。此外,苹果公司的 Swift 和红帽公司的 OpenShift 也稳居前列,显示了成熟商业公司对开源核心技术的持续掌控。
最后,技术风向标指向 AI 与现代化架构。vLLM 作为大模型推理优化的代表项目,以超过 1 万人的开发者规模高居第 12 位,反映了生成式 AI 爆发背景下,底层推理基础设施成为新的竞争高地。传统的系统级项目如 NixOS(第 3)和 LLVM(第 5)依然坚挺,说明可重复构建、编译器优化等基础软件能力仍是开源世界的基石。而 Rust 语言的入围(第 13),则进一步印证了内存安全与高性能并重的系统编程新范式正在被广泛接纳。
为进一步观察头部开源项目背后的地域分布,我们对全球开源项目影响力 Top 100 中可识别发起组织及其所在国家/地区的项目进行了归类统计。需要说明的是,开源项目往往具有跨国协作、多主体共建的特征,且部分项目在公开信息中未明确标注发起组织或组织所在国家/地区,因此下表并非 Top 100 项目的全量国家归属统计,而是基于可识别信息形成的地域分布观察,合计覆盖 78 个可识别项目。
表 3.8 全球开源项目影响力 Top 100 中可识别发起组织项目的国家/地区分布
| 排名 | 国家/地区 | 可识别入选项目数量 |
|---|---|---|
| 1 | 美国 | 49 |
| 2 | 中国 | 12 |
| 3 | 德国 | 3 |
| 3 | 荷兰 | 3 |
| 5 | 俄罗斯 | 2 |
| 6 | 英国、以色列、法国、冰岛、加拿大、南非、挪威、瑞士、保加利亚 | 1 |
从可识别发起组织及其所在国家/地区的项目来看,美国仍然是头部开源项目最主要的来源地,中国位居第二,显示出中美两国在全球开源生态中的突出影响力。
在 Top 100 中的可识别项目范围内,美国项目数量最多,覆盖操作系统、开发框架、云基础设施、开发工具等关键领域,体现出其长期积累的开源生态优势。中国凭借 OpenHarmony、openEuler、MindSpore 等项目形成较强存在感,尤其在基础软件、智能终端操作系统和 AI 框架方向表现突出,说明中国开源生态正在从应用层参与走向基础技术体系建设。德国、荷兰、俄罗斯等国家也有多个项目进入可识别统计范围,英国、以色列、法国、冰岛、加拿大、南非、挪威、瑞士、保加利亚等国家各有代表性项目入选,反映出全球开源生态仍具有广泛的地域多样性。总体来看,在可识别项目范围内,中美项目数量领先,但其他国家和地区也在特定技术方向上保持活跃贡献。
3.3.2 中国开源项目影响力 Top 15:操作系统双核驱动,AI 与大模型生态全面爆发
2025 年中国开源项目排行榜数据显示,中国开源生态已彻底完成从“单点突破”到“体系化引领”的跨越。本期榜单最核心的变化在于,以 OpenHarmony 和 openEuler 为代表的国产操作系统形成了绝对的“双核”领跑态势,两者在 OpenRank 数值上与其他项目拉开了巨大差距。与此同时,人工智能领域呈现出百花齐放的景象,百度、华为、阿里、字节等大厂的大模型框架与工具链密集入榜,标志着中国开源的重心已全面转向“基础软件底座 + AI 原生应用”的双轮驱动模式。
表 3.9 中国开源项目影响力 Top 15
| 排名 | 项目名称 | OpenRank | 开发者规模 | 发起组织 |
|---|---|---|---|---|
| 1 | OpenHarmony | 60,089.18 | 6,487 | OpenAtom Foundation |
| 2 | openEuler | 16,257.57 | 3,285 | OpenAtom Foundation |
| 3 | MindSpore | 8,064.37 | 1,211 | Huawei |
| 4 | PaddlePaddle | 7,305.94 | 3,168 | Baidu |
| 5 | Apache Doris | 4,031.07 | 747 | Apache Software Foundation |
| 6 | ModelScope | 3,681.64 | 3,732 | Alibaba |
| 7 | VolcEngine | 3,638.97 | 3,686 | ByteDance |
| 8 | Ant Design | 3,288.48 | 3,288 | Ant Group |
| 9 | openKylin | 3,180.90 | 773 | OpenAtom Foundation |
| 10 | TiDB | 3,162.02 | 498 | PingCAP |
| 11 | Anolis OS | 2,996.83 | 514 | OpenAtom Foundation |
| 12 | verl | 2,785.19 | 2,875 | ByteDance |
| 13 | StarRocks | 2,770.29 | 762 | StarRocks |
| 14 | Milvus | 2,640.81 | 986 | LF AI & Data Foundation |
| 15 | 1Panel | 2,304.38 | 1,369 | Fit2Cloud |
榜单深度分析:
第一,国产操作系统构建起坚不可摧的“双塔”格局。
OpenHarmony 以超过 6 万的 OpenRank 值断层领先,其得分是第二名 openEuler 的近 4 倍,更是第三名的 7 倍以上。这种压倒性的优势表明,OpenHarmony 已不仅仅是一个项目,而是成为了连接万物互联生态的国家级基础设施。紧随其后的 openEuler 稳居第二,两者均源自开放原子开源基金会,共同构成了中国基础软件在“端侧”与“云侧”的完整闭环。此外,openKylin(第 9)和 Anolis OS(第 11)也位列前十,进一步夯实了国产操作系统族群的整体厚度。
第二,AI 与大模型技术栈成为增长新引擎。
与往年相比,本期榜单中 AI 相关项目的密度显著增加。MindSpore(华为)和 PaddlePaddle(百度)分列第三、第四,保持了国产深度学习框架的第一梯队地位。更值得关注的是大模型时代的新型工具链:ModelScope(阿里魔搭社区)高居第 6,VolcEngine(字节火山引擎)和第 12 位的 verl(字节开源的大模型强化学习库)强势入榜,显示出中国互联网巨头在大模型训练、推理及优化层面的开源力度空前加大。这些项目不仅拥有数千人的开发者规模,更代表了从“通用 AI”向“垂类大模型应用”的技术演进。
第三,数据库与中间件持续深化国产化替代。
在基础数据设施领域,Apache Doris(第 5)、TiDB(第 10)和 StarRocks(第 13)依然表现稳健,证明了中国在分布式数据库领域的全球竞争力。同时,Ant Design(第 8)作为企业级前端解决方案的代表,以及 1Panel(第 15)作为现代化服务器管理面板的入选,反映出开源生态正从底层内核向上层应用开发工具和运维管理工具全面渗透,生态丰富度显著提升。
总体而言,中国开源项目已告别了单一项目的单打独斗,形成了以操作系统为底座、以大模型生态为先锋、以数据库和中间件为支撑的成熟立体化格局。
3.3.3 2025 年中国开源项目影响力跃升先锋榜
我们选取了 2025 年中国开源项目影响力排行榜中,同比排名上升最快且进入 Top 10 的代表性项目,如下表所示:
表 3.10 中国开源项目影响力跃升先锋榜 Top 10
| 排名 | 总排名(上升排名) | 项目名称 | OpenRank(含同比变化) | 发起单位 |
|---|---|---|---|---|
| 1 | 7(+1,582) | verl-project/verl | 2,785.19 (+2,766.84) | 字节跳动 |
| 2 | 45(+484) | alibaba/spring-ai-alibaba | 736.62 (+ 647.68) | 阿里巴巴 |
| 3 | 46(+676) | kvcache-ai/ktransformers | 734.98 (+ 678.99) | 清华大学 |
| 4 | 50(+339) | kwdb/kwdb | 700.98 (+ 573.29) | KaiwuDB |
| 5 | 56(+252) | PaddlePaddle/FastDeploy | 662.22(+490.94) | 百度 |
| 6 | 58(+413) | gpustack/gpustack | 641.9(+537.58) | GPUstack.ai |
| 7 | 63(+437) | XiaoMi/ha_xiaomi_home | 558.72(+463.29) | 小米 |
| 8 | 89(+1,434) | kvcache-ai/Mooncake | 428.71(+409.14) | 清华大学 |
| 9 | 91(+402) | ant-design/x | 420.09 (+323.20) | 蚂蚁集团 |
| 10 | 100(+1,233) | deepseek-ai/DeepSeek-V3 | 394.05 (+370.39) | 深度求索 |
核心发现:
- 字节跳动引领 AI 基础设施开源新范式:
verl-project/verl以 1,582 名的惊人跃升冲至第 7 位,成为 2025 年上升最快的项目。作为火山引擎推出的开源 RLHF(基于人类反馈的强化学习)训练框架,verl首次将大模型对齐训练流程标准化、可复现化,已支撑字节内部多个 AI Agent 产品落地。该项目的爆发式增长,标志着字节跳动正从“内容平台”向“AI 基础设施提供者”深度转型,并在开源社区中建立起技术话语权。 - 高校力量强势入局,清华系项目双星闪耀: 清华大学主导的
ktransformers(+676)与Mooncake(+1,434)双双进入跃升榜前十,分别聚焦 大模型推理优化 与 高效训练调度。其中ktransformers通过灵活的 KV Cache 管理机制,显著降低显存占用;Mooncake则针对千卡集群场景优化通信效率。这两项成果不仅技术指标领先,更以高工程化质量赢得工业界广泛采用,开创了中国顶尖高校通过开源直接驱动产业创新的新路径。 - 企业级 AI 开发工具链加速成熟: 阿里巴巴的
spring-ai-alibaba(+484)将 Agent、Workflow 与多智能体能力无缝集成进 Spring 生态,大幅降低 Java 企业开发 AI 应用的门槛;百度FastDeploy(+252)则聚焦大模型推理部署,全面适配国产芯片,推动 AI 在制造、能源等传统行业落地;蚂蚁集团ant-design/x(+402)虽为 UI 框架,但通过内置 AI 组件(如智能表单、对话式交互),实现前端开发与大模型能力的融合。这些项目共同表明:AI 正从“研究原型”走向“生产就绪”,而中国企业正在定义新一代开发标准。 - 垂直场景开源价值凸显,国产替代纵深推进:
- KaiwuDB 的
kwdb(+339)作为面向 AIoT 的分布式多模数据库,支持时序与关系数据融合处理,已在能源电力、车联网等领域规模化应用,填补了国产数据库在物联网数据管理与智能分析场景的空白; - 小米
ha_xiaomi_home(+437)开源智能家居控制框架,打破生态壁垒,推动 MIoT 与主流家庭自动化平台互通; - GPUStack.ai 的
gpustack(+413)专注 GPU 资源调度优化,解决多模型并发推理中的显存碎片问题,迅速成为 AI 初创公司基础设施标配。 - 开源创新进入“场景定义”时代: 2025 年的跃升项目呈现出鲜明特征——不再追求通用性,而是深度绑定具体场景:从字节的 RLHF 训练、清华的推理优化,到 KaiwuDB 的物联网数据库、小米的智能家居互联,开源正从“技术展示”转向“问题解决”。这一转变意味着,中国开源生态已越过模仿阶段,开始基于本土产业需求原创技术方案,并通过开源反哺全球开发者社区。
3.4 新势力开源项目排行榜
开源生态的活力,不仅来自成熟项目的稳健演进,更源于新生力量的不断涌现。2025 年,在 AI 大模型、智能体(Agent)、隐私计算、RISC-V 工具链、可持续软件工程等前沿领域,一批由中国开发者主导的新势力项目迅速崛起,展现出强大的技术原创性与社区凝聚力。
本节聚焦 2025 年 1 月 1 日后首次发布且表现突出的新项目,发布“新势力开源项目排行榜”。评选标准兼顾增长速度、技术独特性、社区活跃度与长期潜力,特别关注那些由高校团队、初创公司或个人开发者发起,却在短时间内获得国际社区广泛关注的项目。这些“新星”不仅是技术创新的探路者,更是中国开源未来竞争力的晴雨表。通过本榜单,我们希望为投资机构、孵化器、技术媒体提供早期识别信号,也为青年开发者树立“小而美、专而精”的成功范式。
3.4.1 全球新势力开源项目排行榜:AI 领衔,多元绽放
AI 技术持续引领开源创新浪潮,同时在前端、区块链、云基础设施等领域涌现出一批高成长性新项目,以下是全球新势力开源项目排行榜 Top 30:
表 3.11 全球新势力开源项目排行榜 Top 30
| 排名 | 项目名 | 月均 OpenRank | 技术领域 | 主要语言 | 描述 |
|---|---|---|---|---|---|
| 1 | DigitalPlatDev/FreeDomain | 1,219.0694 | 应用与解决方案 | HTML | 人人可享的免费域名服务 |
| 2 | CherryHQ/cherry-studio | 270.4182 | AI & 前端 | TypeScript | 支持多 LLM 提供商的桌面客户端,兼容 deepseek-r1 |
| 3 | ggml-org/llama.cpp | 240.24 | AI & 编程语言与开发 | C++ | C/C++ 环境下的大语言模型推理工具 |
| 4 | stackblitz/bolt.new | 210.928 | AI & 前端 & 云基础设施 | TypeScript | 可快速构建、运行、编辑并部署全栈 Web 应用 |
| 5 | RooCodeInc/Roo-Code | 191.1142 | AI & 编程语言与开发 | TypeScript | 集成于编辑器的 AI 自动编码助手 |
| 6 | elizaOS/eliza | 158.6689 | AI | TypeScript | 面向大众的自主智能代理工具 |
| 7 | cline/cline | 122.1027 | AI & 编程语言与开发 | TypeScript | IDE 内的自主编码代理,经许可可创建 / 编辑文件、执行命令等 |
| 8 | Aider-AI/aider | 116.6952 | AI & 编程语言与开发 | Python | 终端内的 AI 结对编程工具 |
| 9 | All-Hands-AI/OpenHands | 115.2683 | AI & 编程语言与开发 | Python | 助力 “少编码,多创造” 的工具 |
| 10 | erigontech/erigon | 91.0026 | 区块链与 Web3 | Go | 遵循 GNU Lesser General Public License v3.0 协议 |
| 11 | ohcnetwork/care_fe | 90.0266 | 应用与解决方案 | TypeScript | 助力医疗资源跨区域分散管理的数字公益项目 |
| 12 | community-scripts/ProxmoxVE | 89.9397 | 云基础设施 | Shell | Proxmox VE 辅助脚本(社区版) |
| 13 | browser-use/browser-use | 87.7688 | AI & 前端 | Python | 让网站对 AI 代理更友好的工具 |
| 14 | modular/modular | 85.5626 | 编程语言与开发、AI | Mojo | Mojo 编程语言 |
| 15 | ghostty-org/ghostty | 84.8664 | 操作系统 | Zig | 采用原生 UI 和 GPU 加速的跨平台终端模拟器 |
| 16 | pydantic/pydantic-ai | 83.3799 | AI、编程语言与开发 | Python | 用于 LLM 与 Pydantic 结合的代理框架 / 适配层 |
| 17 | iotaledger/iota | 80.6274 | 区块链与 Web3 | Rust | 助力 Web3 与现实世界连接的可扩展去中心化可编程 DLT 基础设施 |
| 18 | volcengine/verl | 80.1939 | AI | Python | 火山引擎大语言模型强化学习工具 |
| 19 | block/goose | 79.8506 | AI & 编程语言与开发 | Rust | 支持安装、执行等操作的开源可扩展 AI 代理 |
| 20 | modrinth/code | 79.1998 | 应用与解决方案 | Rust | 支撑 Modrinth 运行的代码库 |
| 21 | bloxstraplabs/bloxstrap | 79.1061 | 应用与解决方案 | C# | 带额外功能的 Roblox 替代启动器 |
| 22 | apache/gravitino | 78.9191 | 大数据与数据工程、数据库 | Java | 高性能、分布式元数据湖的开源数据目录 |
| 23 | Cumulocity-IoT/c8y-docs | 77.2667 | 物联网与边缘计算 | SCSS | Cumulocity IoT 指南与文档 |
| 24 | RSSNext/Folo | 76.783 | 前端、区块链与 Web3 | TypeScript | 一站式信息聚合工具 |
| 25 | AstrBotDevs/AstrBot | 76.5032 | AI & 应用与解决方案 | Python | 易部署的多平台 LLM 聊天机器人及开发框架,支持工作流、代码执行等 |
| 26 | stackblitz-labs/bolt.diy | 76.2544 | AI & 前端 | TypeScript | 可自定义 LLM 来构建、部署全栈 Web 应用 |
| 27 | luanti-org/luanti | 74.9987 | 应用与解决方案 | C++ | 开源体素游戏创作平台(原 Minetest) |
| 28 | Saghen/blink.cmp | 72.125 | 编程语言与开发 | Lua | Neovim 高性能、功能丰富的补全插件 |
| 29 | modelcontextprotocol/servers | 71.1212 | AI | JavaScript | 模型上下文协议服务端 |
| 30 | huggingface/smolagents | 69.7365 | AI | Python | 轻量智能代理库,代理通过编写 Python 代码调用工具、协调其他代理 |
关键洞察:
- AI 领域独占鳌头:在 Top 30 新势力项目中,与 AI 相关的项目多达 19 个,占据了超过一半的比例。这充分彰显了人工智能在当前开源创新领域的核心地位和强大驱动力。无论是像 CherryHQ/cherry-studio 这样支持多种大语言模型的桌面客户端,还是 bloxstraplabs/bloxstrap 这种 AI 驱动的自动编码代理,都在不断拓展人工智能的应用边界,满足市场对于智能化解决方案的强烈需求。
- 编程语言与开发类项目活跃:有 11 个项目聚焦于编程语言与开发领域。这些项目涵盖了从新兴的 Mojo 语言(modular/modular)到传统的 C++、Python 等语言的开发工具和框架。它们为开发者提供了更加高效、便捷的编程环境和工具,推动着编程语言的发展和应用创新。
- 多领域交叉融合趋势明显:许多项目涉及多个技术领域的交叉融合。例如 stackblitz/bolt.new 融合了 AI、前端和云基础设施;RSSNext/Folo 则结合了前端和区块链与 Web3 技术。这种多领域的融合创新有助于创造出更具综合性和创新性的解决方案,满足用户日益复杂的需求。
3.4.2 技术领域分析:AI 主导创新,多领域协同延伸
对全球新势力开源项目排行榜 Top 30 的技术领域分布进行分析,可清晰看到当前开源创新的核心赛道与趋势特征,具体统计如下:
表 3.12 全球新势力开源项目排行榜 Top 30 技术领域分布
| 技术领域分类 | 项目数量 | 占比 | 平均月均 OpenRank | 代表项目 | 核心应用场景 |
|---|---|---|---|---|---|
| AI 相关领域(含交叉) | 19 | 63.3% | 138.7 | CherryHQ/cherry-studio、ggml-org/llama.cpp | LLM 推理、AI 编码代理、多模态交互 |
| 应用与解决方案 | 7 | 23.3% | 226.5 | DigitalPlatDev/FreeDomain、modrinth/code | 域名服务、游戏开发平台、医疗管理系统 |
| 编程语言与开发(非 AI 交叉) | 2 | 6.7% | 78.8 | Saghen/blink.cmp、modular/modular | 代码补全插件、新型编程语言开发 |
| 区块链与 Web3 | 3 | 10.0% | 80.8 | erigontech/erigon、iotaledger/iota | 以太坊节点、分布式账本基础设施 |
| 云基础设施 | 2 | 6.7% | 150.4 | stackblitz/bolt.new、community-scripts/ProxmoxVE | 全栈应用部署、虚拟化管理脚本 |
| 操作系统 | 1 | 3.3% | 84.9 | ghostty-org/ghostty | 跨平台终端模拟器 |
| 大数据与数据工程、数据库 | 1 | 3.3% | 78.9 | apache/gravitino | 分布式元数据湖 |
| 物联网与边缘计算 | 1 | 3.3% | 77.3 | Cumulocity-IoT/c8y-docs | IoT 文档与分析支持 |
关键洞察:
- AI 成绝对创新核心:AI 相关项目(含 “AI + 前端”“AI + 编程语言与开发” 等交叉领域)占比超 6 成,且平均月均 OpenRank(138.7)显著高于其他领域,其中 ggml-org/llama.cpp(240.24)、stackblitz/bolt.new(210.928)等项目凭借 LLM 技术落地能力,成为新势力中的 “头部玩家”,反映出当前开源创新高度聚焦 AI 技术的产业化应用。
- 应用与解决方案领域 “单项目影响力突出”:该领域虽仅 7 个项目,但平均月均 OpenRank 高达 226.5,主要依赖 DigitalPlatDev/FreeDomain(1,219.0694)的拉动 —— 这款免费域名服务项目因贴近中小企业与个人开发者需求,成为 Top 30 中影响力最高的项目,也说明 “轻量化、实用性” 的应用类项目更易快速获得市场认可。
3.4.3 主要语言分析:TypeScript 与 Python 主导,小众语言精准卡位
全球新势力开源项目排行榜 Top 30 的主要编程语言分布,反映了不同技术场景下的语言选择偏好,具体统计如下。
表 3.13 全球新势力开源项目排行榜 Top 30 主要编程语言分布
| 主要语言 | 项目数量 | 占比 | 平均月均 OpenRank | 适配技术领域 | 代表项目 |
|---|---|---|---|---|---|
| TypeScript | 10 | 33.3% | 156.8 | AI、前端、区块链与 Web3、应用与解决方案 | CherryHQ/cherry-studio、stackblitz/bolt.new |
| Python | 9 | 30.0% | 105.3 | AI、编程语言与开发、应用与解决方案 | Aider-AI/aider、huggingface/smolagents |
| Rust | 4 | 13.3% | 79.9 | 区块链与 Web3、应用与解决方案、AI | iotaledger/iota、block/goose |
| C++ | 2 | 6.7% | 157.6 | AI、应用与解决方案 | ggml-org/llama.cpp、luanti-org/luanti |
| Go | 1 | 3.3% | 91.0 | 区块链与 Web3 | erigontech/erigon |
| Java | 1 | 3.3% | 78.9 | 大数据与数据工程、数据库 | apache/gravitino |
| Mojo | 1 | 3.3% | 85.6 | 编程语言与开发、AI | modular/modular |
| Zig | 1 | 3.3% | 84.9 | 操作系统 | ghostty-org/ghostty |
| Shell | 1 | 3.3% | 89.9 | 云基础设施 | community-scripts/ProxmoxVE |
| SCSS | 1 | 3.3% | 77.3 | 物联网与边缘计算 | Cumulocity-IoT/c8y-docs |
| Lua | 1 | 3.3% | 72.1 | 编程语言与开发 | Saghen/blink.cmp |
| C# | 1 | 3.3% | 79.1 | 应用与解决方案 | bloxstraplabs/bloxstrap |
| HTML | 1 | 3.3% | 1,219.1 | 应用与解决方案 | DigitalPlatDev/FreeDomain |
关键洞察:
- TypeScript 与 Python 成 “双核心”:两者合计占比超 6 成,覆盖 AI、前端、应用开发等核心场景。TypeScript 凭借 “强类型 + 前端适配” 优势,成为 AI 桌面客户端(CherryHQ/cherry-studio)、全栈应用(stackblitz/bolt.new)的首选语言;Python 则依托丰富的 AI 库(如 TensorFlow、PyTorch),在 AI 编码代理(Aider-AI/aider)、LLM 强化学习(volcengine/verl)领域占据主导,两者分别对应 “前端交互” 与 “后端算法” 的核心需求。
- 小众语言 “技术场景精准匹配”:新兴语言 Mojo(modular/modular)因兼顾 Python 易用性与 C++ 性能,成为 AI 编程语言开发的新选择;Zig 语言凭借内存安全与跨平台特性,被用于操作系统终端模拟器(ghostty-org/ghostty);Rust 则因去中心化与高性能,成为区块链项目(iotaledger/iota)的主流语言,这些小众语言虽项目数量少,但在特定技术场景下展现出不可替代性。
- “语言-领域” 绑定关系显著:区块链与 Web3 领域 75% 项目选择 Rust/Go(高性能、去中心化适配);AI 领域 84% 项目选择 TypeScript/Python(快速迭代、库生态丰富);应用与解决方案领域语言最分散(覆盖 HTML、TypeScript、Python 等 6 种语言),反映出该领域更注重 “用户需求适配” 而非 “技术性能优先”,语言选择更灵活。
四、开源专题分析
4.1 大模型生态分析
4.1.1 什么是大模型生态?
在全球范围内,Hugging Face 是最具影响力的开源大模型平台之一;在中国,功能定位相近的平台则是 ModelScope(魔搭社区)。开发者和研究机构可以在这些平台上发布模型、完善模型说明、披露许可协议,并通过下载、点赞、评论等互动方式,形成持续活跃的社区反馈机制。与前几章主要依托 GitHub 等平台观察代码层面的协作不同,本章将视角转向大模型生态,关注的重点不再是“代码如何被共同维护”,而是“模型发布后如何被使用、被关注,以及如何在已有模型基础上进行二次开发与创新”。
本章按照时间线展开。第一部分聚焦 2022—2025 年的长期变化,重点分析平台上的模型增长、模型类型结构、衍生关系、模型许可信息、协作社区以及中国模型和机构在其中的位置;第二部分聚焦 2025-03 至 2026-02 的月度变化,重点分析最近一年中哪些模型被持续使用、哪些模型更容易获得关注,以及关键月份的变化如何形成。
4.1.2 主要发现
- 平台规模持续扩大:截至 2025 年底,Hugging Face 已拥有超过 1,300 万用户和 250 万个模型;ModelScope(魔搭社区)则吸引了超过 1,600 万用户,托管模型逾 15 万个。两大平台均呈现出指数级增长态势。
- 模型扩张并非平均发生。 在规模增长的同时,平台上的模型结构正进一步向少数主流模型类型集中。其中,文本生成是最清晰的增长主线,图像生成、语音识别以及多模态相关方向也在持续扩张,平台主流能力方向正在逐步明确。
- 模型生态正在从“发布”走向“复用”。 最近两年,围绕已有模型继续进行微调、适配和量化的行为明显增加,说明平台生态的重点已经不再只是发布新模型,而是越来越多地围绕基座模型展开持续复用和再开发。
- 许可信息完整性问题更加突出。 随着模型复用路径增多,模型许可是否清晰、是否能够支持后续复用判断,正在成为平台生态中的一个现实问题。特别是在部分复用类型中,许可信息缺失仍较为普遍。
- 头部模型越来越呈现社区化特征。 高影响力模型不再只是“发布后被下载”,而是在持续接收反馈、展开讨论并迭代更新。模型仓库正逐步从单纯的模型页面,演变为持续运营的社区入口。
- 最近一年的“使用”与“关注”并不相同。 2025-03 至 2026-02 的月度数据表明,下载更适合反映哪些模型被持续接入和反复使用,点赞更适合反映哪些模型在某一时间窗口获得集中关注和认可,两者不能简单等同。
- 中国模型的影响力明显上升。 从机构榜单、协作热度和关键月份代表模型来看,Qwen、DeepSeek、GLM、Kimi 等中国模型和机构已不再只是平台中的活跃参与者,而正在成为 Hugging Face 生态变化中的重要力量。
4.1.3 2022—2025:Hugging Face 平台上的模型生态变化
1. 模型和发布者持续增长
为了更直观地看清 Hugging Face 平台扩张是否同时发生在“模型数量”和“发布者数量”两个层面,可以先从年度新增数据进行观察。如图 4.1 所示,2022—2025 年间,年度新增模型与新增模型发布者均呈明显上升趋势。
说明:本图按模型发布时间统计新增数量。“新增模型”是当年首次发布到 Hugging Face 的模型数;“新增模型发布者”是当年首次发布模型的不同作者数。二者同步增长,说明平台扩张并不只是老作者重复发模型。
从年度新增看,2022 到 2025 年,Hugging Face 年度新增模型由 10 万级增加到 117 万,新增模型发布者也由 3 万扩大到 20 万以上。与此同时,作为中国本土重要的开源模型社区与模型服务平台,ModelScope(魔搭社区)同期也呈现出明显的平台扩张趋势。
结合 Hugging Face 与 ModelScope 两个平台可以看到,开源模型生态的扩张不仅发生在全球平台,也正在中国本土平台同步展开;模型供给的增长,正在由少数机构集中发布,进一步转向更多组织与个人持续参与的常态化供给。
2026 年的 1—2 月,平台已新增 29.5 万个模型和 3.6 万个模型发布者,表明 2026 年初 Hugging Face 的模型供给规模仍然保持在较高水平。
如果把观察尺度进一步细化到月份,可以更清楚地看到平台扩张并不是一次性跳升,而是逐步积累并在不同阶段出现提速。如图 4.2 所示,2022 年 3 月至 2026 年 1 月的月度新增模型数量变化呈现出较为明显的阶段性特征。
说明:横轴表示模型发布时间所在月份,纵轴表示当月新增模型数量。曲线越高,表示该月新发布到平台的模型越多。
2022—2023 年,月新增模型总体持续上升;2024 年下半年出现新一轮提速;2025 年大部分月份保持在较高水平。这表明 Hugging Face 的模型增长已经从早期的阶段性扩张,转向更稳定、更持续的增长。
2. 活跃协作者持续增长,平台社区基础总体扩大
除了看新增模型数量,还需要进一步观察平台的协作基础是否在同步扩大。Hugging Face 不只是模型越来越多,还需要看有多少人真正参与了协作、有多少模型仓库真正形成了持续互动。如图 4.3 所示,2022—2025 年间,平台新增活跃协作者数量持续增长,活跃模型仓库总体上也呈扩大趋势。
说明: 左图展示 2022—2025 年每年新增的活跃协作者数量;右图展示 2022—2025 年每年的活跃模型仓库数量。这里的 “活跃协作者” 指在 Hugging Face 模型仓库中有协作行为记录的用户,例如发起或参与 Discussion、PR、评论、回复、编辑、表情反馈等;仅注册但没有协作行为记录的用户,不计为活跃协作者。“活跃模型仓库” 指在统计期内发生过协作行为记录的模型仓库。
从结果看,Hugging Face 的社区基础在最近几年总体持续扩大。截至 2025 年年底,平台已累计拥有 168,179 名活跃协作者 和 218,699 个活跃模型仓库。其中,年度新增活跃协作者由 2022 年的 6,768 人 增长到 2025 年的 62,805 人,说明越来越多用户不再只是浏览和下载模型,而是开始参与反馈、讨论和协作。与此同时,活跃模型仓库数量在 2025 年达到 127,139 个,明显高于此前几年,表明平台上的协作行为已不再局限于少数头部仓库,而是在更大范围内扩展开来。
需要注意的是,Hugging Face 2024 年活跃模型仓库数量较 2023 年出现阶段性回落,但这并不意味着平台协作整体降温。进一步核查显示,2024 年平台协作事件总数由 24.68 万 增长到 31.77 万,活跃协作者也由 2.17 万 增长到 2.95 万,说明协作行为本身并未减少。与此同时,单个活跃仓库平均承载的协作事件数由 4.37 提升到 8.04,Top 10、Top 50、Top 100 仓库的协作占比也明显上升,表明 2024 年的协作更集中在较少但更活跃的重点仓库之中。换言之,2024 年更适合被理解为平台协作向核心仓库集中的阶段,而不是平台整体活跃度走弱。
整体来看,这一变化说明,Hugging Face 的生态增长并不只是模型供给增加,也包括围绕模型产生协作的社区基础不断加厚。这为后续的模型复用、问题反馈、持续迭代和社区运营提供了更扎实的底座。
结合 Hugging Face 与 ModelScope 两个平台可以看到,当前开源模型生态的扩张,正在同时表现为“模型供给持续增加”和“围绕模型的社区协作持续增厚”两个过程。
3. 模型增长开始向少数重点模型类型集中
模型类型:指 Hugging Face 对模型主要用途的分类标签,例如 text-generation(文本生成)、text-to-image(文生图)、automatic-speech-recognition(语音识别)等。它不是算法结构分类,而是更接近“这个模型主要用来做什么”。本节涉及到的主要模型类型有:
- text-generation(文本生成):输入一段文字提示,模型继续生成新的文字内容。 例如,输入“请写一段关于低碳城市的摘要”,模型输出一段完整说明;输入代码注释,也可以继续生成代码。
- text-classification(文本分类):给一段文字打标签。 例如,把一条评论判定为“正面/负面”,或把一封邮件判定为“投诉/咨询/广告”。
- text-to-image(文生图):输入文字描述,生成对应图像。 例如,输入“云上的维多利亚风格城市”,模型输出一张符合描述的图片。
- automatic-speech-recognition(语音识别):把语音转成文字,也常写作 ASR 或 Speech-to-Text。 例如,输入一段会议录音,模型输出逐字转写文本。
- reinforcement-learning(强化学习):模型通过和环境反复交互、根据奖励信号学习策略。 例如,让一个智能体在游戏环境中不断试错,逐渐学会如何更快到达目标。
- token-classification(词元分类):给文本中的“词”或“字词片段”逐个打标签。 例如,在“李雷今天去了北京”这句话里,把“李雷”标为人名,把“北京”标为地名。
- image-classification(图像分类):给整张图片判定一个类别。 例如,输入一张猫的照片,模型输出“Egyptian cat”或“tabby cat”等类别。
- feature-extraction(特征提取):不直接输出最终答案,而是把文本、图像等输入转换成向量表示,供检索、聚类、相似度计算等下游任务使用。 例如,把一段用户问题转换成向量,再去知识库里寻找语义最接近的文档。
- image-text-to-text(图文到文本):同时输入图片和文字提示,输出文字。 例如,输入一张图片并问“图中蜜蜂在什么位置?”,模型输出一段文字解释。它比单纯图像描述更灵活,因为还能结合提问或对话上下文。
- fill-mask(掩码填空):给一句话中的某个空缺位置补词。 例如,输入“Paris is the [MASK] of France”,模型预测 [MASK] 应该是 “capital”。
- text-to-video(文生视频):输入文字描述,生成一段视频。 例如,输入“一个宇航员在月球上慢慢行走”,模型输出一段对应场景的视频片段。
- image-to-video(图生视频):输入一张静态图片,生成动态视频;有时也可以再配合文字提示控制运动方式。 例如,输入一张企鹅图片,并提示“这只企鹅在跳舞”,模型输出企鹅动起来的视频。
- image-to-image(图到图):输入一张图片,对它进行变换或增强,输出另一张图片。 例如,把一张低清图片变成高清图,或者把照片改成动漫风格。
- text-to-speech(文转语音):输入文字,生成自然语音。 例如,输入一段新闻稿,模型输出一段可以直接播放的播音语音。
- any-to-any(任意到任意):能够理解多种输入形式,并输出多种形式结果的多模态模型。 例如,输入“视频 + 语音 + 文字提示”,模型既可以输出文字回答,也可以输出语音回复,甚至生成动作指令。这类模型更接近“一个模型同时处理多种感知与生成任务”。
- question-answering(问答):根据给定上下文或问题直接输出答案。 例如,输入一段政策文件,再问“补贴对象是谁?”,模型从文中提取或生成答案。
- robotics(机器人):用于机器人感知、决策和动作控制的模型,通常会结合视觉、语言指令和机器人状态来生成动作。 例如,输入“把桌上的积木放进盒子里”这样的自然语言指令,再结合摄像头画面和机械臂状态,模型输出一段抓取和放置动作。Hugging Face 的 LeRobot 项目就专门面向这类真实机器人学习场景。
仅看模型总量增长,还不足以说明平台上的主流能力方向发生了什么变化。要理解模型扩张是否集中到少数主流类型,还需要先看当前已标注模型的整体结构。如图 4.4 所示,平台上的已标注模型类型分布已经呈现出较为明显的集中格局。
说明: 扇区大小表示某一模型类型在已标注模型数量中的占比。例如,text-generation 的占比表示被标注为文本生成模型的数量,在全部已标注模型中的比重。图中不包含未标注模型。
按模型数量占比看,text-generation 是当前最核心的模型类型,text-classification 和 text-to-image 分列其后,reinforcement-learning、automatic-speech-recognition 等方向也占有一定比重。进一步看,前十类模型合计已占已标注模型的近九成,说明平台上的模型扩张并非分散发生,而是主要围绕生成式、内容理解与内容生产相关方向展开。
说明:当前仍有相当数量模型 未填写模型类型标签。根据现有数据,未标注模型约 180.2 万个,占全部模型的约 68.3%,因此本节对结构变化的判断主要基于 已标注模型 展开,更适合用来理解主流模型类型的变化方向,而不适合将其视为平台全部长尾模型的完整结构。
除了看当前存量结构,更重要的是观察新增模型结构如何变化,因为这更能反映平台主流方向的演化趋势。如图 4.5 所示,不同模型类型在年度新增模型中的占比变化,能够更直接地反映哪些方向正在成为新的增长主线。
说明:横轴表示年份,纵轴表示各模型类型在当年新增模型中的占比。某一类型占比上升,表示它在新增模型中的相对重要性提高。
text-generation 的新增占比从 2022 年的约 15.6% 提升到 2024—2025 年的约 45%—47%,已经成为最清晰的增长主线。text-classification、token-classification 等传统模型类型仍然存在,但在新增中的相对占比已明显回落。
4. 核心模型类型地图:哪些模型更常被使用,哪些模型更容易获得认可
除了看模型数量和模型类型占比,还可以把“被用”和“被赞”放在同一坐标系中,进一步理解不同模型类型在平台中的角色。这里的“被用”主要看下载,“被赞”主要看点赞。核心模型类型地图的意义,不是简单判断哪个类型规模最大,而是区分哪些模型更像基础设施,哪些模型更容易形成体验反馈,哪些方向值得继续跟踪。
为了更清楚地呈现平台上的主流模型类型分布,本节对用于绘制“核心模型类型地图”的模型集合进行了筛选:仅保留累计下载量不少于 1,000 次或至少获得 1 个点赞的模型。按这一口径,共纳入 267,328 个模型,约占全域模型总数的 8.8%。
如果进一步把“被使用”和“被认可”放在同一张图中观察,不同模型类型在平台中的功能分工会更清楚。如图 4.6 所示,核心模型类型在下载与点赞两个维度上的位置并不相同,这有助于区分哪些类型更偏基础设施,哪些类型更偏体验驱动。
(1)三类值得重点识别的模型类型
第一类是基础设施型模型。这类任务在各类系统和流程中被频繁调用,但用户未必会专门回到模型页表达认可。token-classification、image-classification、feature-extraction 等更接近这一角色:它们的下载量较高,但点赞相对有限,反映的是稳定复用而非强话题性。
第二类是体验驱动型模型。text-to-video、image-to-video、image-to-image、text-to-speech、any-to-any 等方向更容易引发“使用后主动点赞”的行为。这类任务的共同点是输出效果更直观,用户更容易形成明确的主观评价,因此在点赞侧通常更活跃。
第三类是兼具通用性与可见度的中间层模型。text-generation、automatic-speech-recognition、feature-extraction 等既有稳定需求,也具备较强的场景扩展能力,因此在下载和点赞两个维度上都保持较高存在感,是当前平台任务结构中的中坚部分。
(2)几个值得继续跟踪的方向
- 语音方向值得持续跟踪。 automatic-speech-recognition 在使用侧已经较为稳固(平均累计下载 ≈ 3.1 万,点赞 ≈ 17),text-to-speech 在点赞侧又更活跃,说明语音相关能力正在从“识别”进一步走向“生成、交互和工作流接入”。
- 跨模态方向值得持续跟踪。 any-to-any 任务虽然核心模型占比不到 0.3%,但在所有任务中 平均累计点赞最高 之一,点赞密度也位居前列。这说明“端到端多模态工作流”虽然还在早期阶段,但用户黏性极强,是值得重点跟踪的新方向。
- robotics 这类小体量、高口碑方向值得长期观察。 robotics 的平均累计下载并不高,但点赞密度很高,说明这类任务虽然用户群体更专业、更小众,但使用者更愿意给出正反馈。并且,Hugging Face 官方也指出,robotics 数据集已经成为平台增长最快的子社区之一,相关工具链和社区也在同步扩张。这说明 robotics 并不是一个孤立的小众标签,而更可能代表 Hugging Face 上一个正在快速成形的“模型—数据—工具”复合型生态方向。
- 传统问答和强化学习仍有稳定需求。 question-answering、reinforcement-learning 的平均累计下载在千级到几千级,点赞密度中等(约 9–13 赞 / 1 万下载),位置偏图中部略偏下。这类任务仍然有稳定需求,但相比图像 / 视频 / 语音创作,话题热度和用户喜好明显弱一些,说明平台上的热点正在更多地转向直接面向应用体验的方向。
5. 模型复用越来越普遍,衍生关系快速增长
模型生态是否正在从“发布新模型”转向“围绕已有模型持续复用”,可以从衍生关系的数量和结构变化中得到更直接的观察。如图 4.7 所示,2022—2025 年间,不同衍生关系的规模和占比都发生了明显变化。
左图反映各类衍生关系对应的“子模型—父模型”边数量,数量越多,说明这一类基于已有模型继续开发的方式越常见;右图反映同一年内各类衍生关系在全部衍生关系中的占比,表示平台上模型复用方式的相对结构。其中:
- finetune 指在已有基础模型上继续用特定数据进行训练,使模型更适应某一领域或任务。例如,在通用大模型基础上继续训练一个“法律问答模型”或“医疗文本分类模型”。它通常表示“在原模型能力基础上做定向增强”。
- adapter 指不直接改动整个基础模型,而是在原模型外增加一小部分可训练模块,用较低成本实现任务适配。例如,在同一个基础模型上分别挂接“翻译适配器”“摘要适配器”或“代码生成适配器”。它通常表示“轻量化复用”,适合快速扩展多个场景。
- quantized 指将模型参数从高精度表示压缩为更低精度,以减少存储和计算开销,便于本地部署或在资源受限环境中运行。例如,把一个原本需要较大显存的模型压缩成 8-bit 或 4-bit 版本,以便在消费级显卡或边缘设备上运行。它通常表示“面向部署和推理效率的改造”。
- merge 指将两个或多个已有模型的参数或能力进行合并,形成一个新的模型。例如,把一个擅长代码的模型和一个擅长通用对话的模型进行合并,希望同时保留两者优势。它通常表示“能力组合型复用”。
从图中可以看出,平台上的模型衍生方式正在由早期以 finetune 为主,逐步转向 finetune、adapter、quantized 并行发展的格局。尤其是 2024—2025 年,adapter 和 quantized 的增长明显加快,说明模型复用已经不再只是“继续训练”,而是进一步扩展到轻量适配和部署优化;merge 虽然规模相对较小,但也持续存在,表明“能力组合”正在成为平台上一类稳定但相对小众的衍生路径。
此外,从平台官方公开数据看,围绕基础模型进行再开发的趋势已经非常明显。Hugging Face 官方指出,阿里巴巴作为组织的衍生模型数量已超过 Google 和 Meta 之和,其中仅 Qwen 家族就对应 11.3 万多个衍生模型;若按带有 Qwen 标签的模型仓库统计,数量已超过 20 万。这说明平台生态的增长,越来越体现为围绕强基座模型展开的持续复用和再开发。
6. 模型复用增加,也让模型许可信息完备度问题更加突出
模型被频繁继续开发和继续复用,体现了生态成熟度的提升,但也带来一个现实问题:不少模型并未完整披露后续复用所需的关键信息。尤其是当模型已经不再停留于“原始发布”,而是不断被适配、再训练、量化和合并时,许可信息是否清晰,直接关系到后续开发者能否判断其可复用边界。如图 4.8 所示,不同模型衍生类型下的许可信息状态分布并不相同,这也反映出平台在模型复用加快的同时,信息完备度并未同步提升。
从图中可以看出,不同复用类型在许可信息状态上存在明显差异。quantized 和 finetune 中,“子模型与父模型许可一致”的占比分别为 61% 和 55%,说明这两类常见复用方式的许可延续相对更稳定;但与此同时,二者中仍分别有 33% 和 30% 的关系属于 Unknown,表明许可信息缺失并不少见。相比之下,adapter 和 merge 的许可信息缺失更为突出,Unknown 占比分别达到 58% 和 68%,均高于“同许可证”占比。整体来看,平台上的模型复用正在不断增加,但许可信息的完整披露并未同步跟上,尤其是在轻量适配和模型合并等复用路径中,这一问题更加明显。
7. 头部模型越来越呈现出社区化运营特征:Discussion 驱动为主
除了模型文件本身,社区互动也越来越重要。高影响力模型往往不是“发布后即结束”,而是持续接收反馈、处理问题并迭代更新,其模型仓库逐步演化为持续运营的社区入口。为了更直观地观察这一点,可以进一步看协作热度最高的模型及其协作话题结构。如图 4.9 所示,2025 年头部模型的协作行为已经呈现出较明显的社区化特征。
说明:左图展示 2025 年协作热度最高的 20 个模型仓库。这里的 Collaboration score 用来衡量模型仓库在一定时间窗口内的协作活跃度,综合考虑了活跃参与者、讨论与 PR 主题、回复、编辑和表情反馈等行为。右图展示这些头部模型仓库中的协作话题结构,其中 Discussion 代表使用反馈和讨论交流,PR 代表合并请求相关协作。
从图中可以看出,2025 年协作最活跃的模型大多已经形成了 “百人级” 参与的社区。左图所列 Top 20 模型中,活跃协作者 普遍在两百人左右,部分模型超过三百人,说明头部模型的竞争已不只是模型能力本身,还包括持续响应问题、吸收反馈和维护社区的能力。
从协作结构看,头部模型仓库的互动明显以 Discussion 为主,绝大多数模型的讨论占比都高于 PR,占据协作主题的主要部分。这说明当前 Hugging Face 上高热度模型的协作,更多不是围绕传统代码仓库式的合并流程展开,而是围绕模型使用反馈、效果讨论、问题排查和快速迭代展开。换言之,模型社区的“运营型协作”正在变得比单纯的代码提交更重要。
值得注意的是,进入协作热度 Top 20 的模型,集中分布在 2025 年关注度较高的一批头部模型和生态中,例如 Grok、GLM、Qwen、DeepSeek 等。这表明,当前平台上的头部模型一旦形成“高关注 + 高讨论 + 持续反馈”的组合,往往更容易进一步放大其传播和扩散效应。
8. 中国开源模型正在成为平台生态中的重要力量
如果把观察视角从单个模型扩展到机构层面,中国开源模型在 Hugging Face 上的位置会更加清楚。不同于单个模型的阶段性波动,机构层面的下载量和点赞量更能反映一个组织在平台上的持续影响力。如图 4.10 所示,中国机构已经同时进入累计下载和累计点赞的头部榜单。
说明:左图展示累计下载量最高的 15 个机构,更多反映“哪些机构的模型被持续使用和集成”;右图展示累计点赞量最高的 15 个机构,更多反映“哪些机构更容易获得社区关注和认可”。同一机构是否同时进入两类榜单,可以用来观察其“实际复用价值”与“社区关注度”是否兼备。
从左图看,累计下载榜前列更多集中在长期提供基础模型能力的组织,如 sentence-transformers、google-bert、openai、FacebookAI 等。这类机构的模型往往承担文本表示、编码器、基础识别或通用底座等角色,因此更容易在不同应用流程中被反复调用。值得注意的是,Qwen、BAAI 等中国机构已经进入累计下载 Top 15,说明中国模型不仅在发布数量上活跃,也已经进入平台长期复用体系。
从右图看,点赞榜更能反映机构在社区中的关注度和品牌影响力。在这一榜单中,Qwen 位列第一,deepseek-ai 进入前三,zai-org 也进入前列,说明中国模型在全球开发者社区中的可见度和认可度已经明显提升。与下载榜相比,点赞榜更容易体现“谁正在被讨论、被关注、被记住”。
将两张榜单放在一起看可以发现,在 Hugging Face 上,“被持续使用”和“被高度关注”并不是同一回事:前者更偏向基础能力和长期集成价值,后者更偏向社区热度和品牌认知。但中国机构已经同时出现在这两类榜单中,这说明中国模型正在从“活跃参与者”进一步走向“既可复用、也受关注”的平台重要力量。
此外,从 Hugging Face 官方在 2026 年 3 月发布的公开综述看,中国模型在平台上的全球影响力已经进一步增强。官方指出,中国已在月度下载和总体下载上超过美国,在过去一年中,中国模型占平台总下载的 41%,形成了最大的单一份额;同时,2025 年中国 AI 生态明显转向开源,百度在 Hub 上的模型仓库数量由 2024 年的零发布增至 2025 年超过 100 个,字节和腾讯的发布量也分别增长了 8—9 倍。这说明中国模型的影响力已不仅体现为个别头部机构的突出表现,而是在平台整体生态中形成了更强的系统性存在。
4.1.4 2025-03 至 2026-02:下载量与点赞量说明了什么
1. 为什么需要同时看下载量和点赞量
要理解最近一年平台活跃度的变化,仅看单一指标并不够,还需要把下载与点赞放在同一时间框架下进行对照观察。如图 4.11 所示,2025-03 至 2026-02 期间,两类指标虽然整体方向一致,但变化节奏并不完全相同。
说明:
- 由于 2026 年 1—2 月的下载和点赞净增量显著高于此前月份,图中采用断轴方式展示,以同时保留 2025 年多数月份的变化细节和 2026 年初的高值变化。
- 本图中的“月度下载净增量”“月度点赞净增量”表示与上月相比新增的下载和点赞数量,更适合观察月度变化;它不是累计总量。例如,某月下载净增量较高,表示该月模型被新增调用、部署或接入的规模更大;某月点赞净增量较高,则表示该月更容易出现集中关注、集中认可或社区讨论升温。
下载更接近模型是否被持续接入产品、脚本、工作流和本地部署方案,因此更能反映平台上的实际复用规模;点赞更接近模型是否在某一时间窗口获得集中认可,因此更能体现新模型、新能力和社区讨论热度。
具体看,2025 年 4—5 月平台已出现一轮明显放量,7 月再次上升;到 11 月,下载和点赞同时显著跃升,其中下载净增达到 42.76 亿次,点赞净增达到 58.48 万次,明显高于此前多数月份。进入 2026 年后,月度增量进一步放大:1 月下载净增升至 507.07 亿次、点赞净增升至 196.17 万次;2 月又进一步升至 2,049.69 亿次 和 729.62 万次。这说明平台热度并不是匀速上升,而是会围绕重点模型的集中发布、快速扩散和持续讨论,形成阶段性高点。
从 Hugging Face 官方公开综述看,也出现了类似趋势:开源模型的关注度通常在发布后迅速达到峰值,平均高关注周期约为 6 周,随后明显放缓。因此,点赞和热度更容易在新模型发布或连续更新时形成集中峰值,而长期下载表现则更能反映模型是否真正进入持续复用。
2. 头部集中度:使用更集中,偏好更分散
除了看月度总量变化,还需要进一步判断这些增量是集中在少数头部模型,还是分散到更广泛的模型群体中。如图 4.12 所示,下载侧与点赞侧的 Top 20 集中度存在较为稳定的差异,这有助于理解“使用”与“关注”在平台上的不同结构。
说明:这里的 Top 20 集中度,指某个月全站新增下载量或新增点赞量中,排名前 20 的模型合计占了多大比例。占比越高,说明该月的增长越集中在少数头部模型上;占比越低,则说明更多增量分散到了中腰部和长尾模型中。
从月度集中度看,下载侧的头部集中度明显高于点赞侧。2025 年 3 月至 2026 年 2 月,下载 Top 20 占比大多在 30%—49% 之间,说明平台每月新增下载中,通常有三到近五成由少数头部模型贡献。Hugging Face 官方也指出,约一半模型的累计下载不足 200 次,而下载量最高的前 200 个模型合计占到全站总下载的 49.6%。这说明平台上的使用行为本身就具有较强的头部集中性,月度 Top 20 集中度的变化更多反映的是这种长期结构在不同月份中的强弱起伏。
相比之下,点赞 Top 20 占比大多仅在 12%—24% 之间,显著低于下载侧,说明社区关注和认可更容易分散到更多不同类型的模型上。
进一步看,下载集中度在 2025 年 3—6 月相对较高,随后在 7 月以后整体有所回落,并在 2025 年 11 月和 2026 年 2 月降至 30.7%。这表明,尽管头部模型仍是平台使用增长的重要来源,但随着更多模型进入实际应用,新增下载正在逐步被更广泛的模型分担。相比之下,点赞集中度始终维持在较低水平,尤其 2025 年 7 月仅为 12.1%,说明用户在表达认可时,并不会只集中于少数最热门模型,而更愿意把注意力分配给不同方向的“新能力”和“新体验”。
整体来看,“被持续使用”与“被集中偏好”并不是同一种结构:下载更容易被头部模型主导,反映的是平台复用体系的集中性;点赞则更容易扩散到更多模型,反映的是社区注意力和口碑反馈的分散性。这也意味着,在 Hugging Face 上,真正形成长期复用基础的模型未必就是当月最受关注的模型,而创新方向和新体验更容易在点赞侧率先体现出来。
3. 常驻模型:长期支撑流量的是可复用的中间层能力
如果进一步观察哪些模型能够长期、反复地进入月度下载 Top 20,就可以更清楚地识别平台中真正支撑长期复用的模型。如表 4.1 所示,真正长期支撑平台流量的,并不主要是当期最热门的对话模型,而是文本嵌入、经典编码器、视觉 backbone、安全识别等可反复调用的中间层能力。
说明:这里的“出现月份数”指某个模型在 2025-03 至 2026-02 的月度 Top 20 榜单中出现了多少个月;而“Top 20 内下载增量合计”或“Top 20 内点赞增量合计”指该模型在进入 Top 20 的那些月份里,合计贡献了多少下载或点赞增量,它反映的是模型在“头部榜单中的累计贡献”,而不是模型在平台上的历史累计总量。
表 4.1 下载 Top 20 常驻模型(按出现月份数,Top 10)
| 模型 | 出现月份数 | Top 20 内下载增量合计(次) |
|---|---|---|
| sentence-transformers/all-MiniLM-L6-v2 | 12 | 610,686,941 |
| sentence-transformers/all-mpnet-base-v2 | 12 | 118,761,995 |
| timm/mobilenetv3_small_100.lamb_in1k | 12 | 96,084,260 |
| Falconsai/nsfw_image_detection | 12 | 28,595,149,095 |
| google-bert/bert-base-uncased | 12 | 284,177,818 |
| dima806/fairface_age_image_detection | 12 | 120,792,157 |
| openai/clip-vit-large-patch14 | 9 | 80,970,480 |
| facebook/opt-125m | 9 | 40,768,170 |
| openai/clip-vit-base-patch32 | 8 | 75,817,891 |
| FacebookAI/roberta-large | 8 | 26,865,275 |
例如,sentence-transformers/all-MiniLM-L6-v2、sentence-transformers/all-mpnet-base-v2、google-bert/bert-base-uncased、timm/mobilenetv3_small_100.lamb_in1k 等模型,在最近一年中多次甚至持续进入月度下载 Top 20;其中有些模型连续 12 个月上榜。这说明,平台上的稳定下载需求很大一部分来自“底层能力组件”,它们未必最受关注,但更容易被集成到检索、分类、识别、审核和工作流中,因而具有更强的长期复用价值。
与下载常驻模型相比,点赞常驻模型更能反映哪些模型持续获得社区关注和认可。如表 4.2 所示,能够长期进入点赞 Top 20 的模型,更多集中在图像生成、推理增强和语音交互等更容易形成体验反馈的方向。
表 4.2 点赞 Top 20 常驻模型(按出现月份数,Top 10)
| 模型 | 出现月份数 | Top 20 内点赞增量合计(次) |
|---|---|---|
| black-forest-labs/FLUX.1-dev | 6 | 1,683 |
| Phr00t/Qwen-Image-Edit-Rapid-AIO | 4 | 1,481 |
| hexgrad/Kokoro-82M | 4 | 888 |
| Tongyi-MAI/Z-Image-Turbo | 3 | 3,231 |
| deepseek-ai/DeepSeek-R1-0528 | 3 | 1,853 |
| google/gemma-3n-E4B-it-litert-preview | 3 | 1,310 |
| ResembleAI/chatterbox | 3 | 882 |
| lodestones/Chroma | 3 | 836 |
| deepseek-ai/DeepSeek-R1 | 3 | 722 |
| deepseek-ai/DeepSeek-R1-0528-Qwen3-8B | 3 | 614 |
例如 FLUX.1-dev、Qwen-Image-Edit-Rapid-AIO、Kokoro-82M、DeepSeek-R1 等。它们虽然在某些月份可以形成明显的口碑峰值,但持续上榜月份整体少于下载常驻模型,说明点赞更容易围绕阶段性热点形成集中反馈,而不像下载那样长期由少数基础能力稳定支撑。
整体来看,下载榜回答的是“哪些模型被持续用起来了”,点赞榜回答的是“哪些模型持续被看见、被讨论、被认可了”。前者更稳定、更偏底层基础设施,后者更容易被新体验和新能力撬动。
4.1.5 总结与评论
综合来看,2022—2025 年间,Hugging Face 上最突出的长期变化,是模型数量与模型发布者数量同步增长。平台已经不再只是少数头部团队集中发布模型的托管空间,而是逐步演变为大量个人与机构持续参与的公开模型分发与复用平台。
在规模扩张的同时,平台上的模型结构并没有持续分散,而是逐步向少数主流模型类型集中。文本生成、图像生成、语音识别等与生成式、多模态和内容生产相关的方向,正在成为更清晰的增长主线。这说明 Hugging Face 上的模型扩张,不只是“模型更多了”,而是平台上的主流能力方向正在进一步明确。
与此同时,模型生态的演化也不再停留于“发布一个模型”本身。衍生关系持续增加、许可信息完整性不足,以及头部模型日益明显的社区化运营特征,都表明平台正在从“模型发布平台”进一步走向“围绕模型持续开发、持续反馈和持续复用”的生态平台。
从 2025-03 至 2026-02 的月度表现看,下载量与点赞量反映的是两种不同但互补的信号。下载更接近模型是否被持续接入和反复使用,点赞更接近模型是否在某一时间窗口获得集中关注与认可。近一年中若干关键月份的明显波动,也表明平台热度往往会围绕重点模型集中发布、快速扩散和持续讨论而形成阶段性高点。
最后,从机构、模型和关键月份的综合表现看,中国模型已经不再只是平台中的活跃参与者,而是逐步进入头部机构榜单、协作热度榜单以及关键月份代表模型名单,成为当前 Hugging Face 生态变化中的重要推动力量之一。
4.2 开源之夏年度分析
4.2.1 背景介绍与宏观分析
开源之夏 OSPP 是中国科学院软件研究所发起的“开源软件供应链点亮计划”系列暑期活动,旨在鼓励高校学生积极参与开源软件的开发维护,促进优秀开源软件社区的蓬勃发展,至今已成功举办六届(2020—2025)。
根据 OSPP 社区的数据报告,2025 年度,OSPP 总共发布了项目 565 个,有学生中选项目共计 517 个,最终结项项目为 436 个,结项率为 77%。发布项目总数相较 2024 年基本持平,在更严格的筛选下,中选项目与结项数量均略有降低。相较 2024 年,参与的高校数量也略有下降。
表 4.3 OSPP 2025 年度总体情况
| 项目总数 | 中选项目数 | 结项项目数 | 结项率(%) | 高校数量 |
|---|---|---|---|---|
| 565(+3) | 517(-2) | 436(-19) | 81(-4) | 165(-21) |
最终结项项目中,除了个别与操作系统内核相关的社区使用了自己的 Git 仓库外,大部分社区均托管于 GitHub(307 个)、Gitee(86 个)、AtomGit(30 个)等代码托管平台上。值得注意的是,AtomGit 平台在快速崛起,明显挤压了 Gitee 的项目数量,平台的总体分布如下:
从结项项目的学生所属高校来看,结项的 436 个项目由分别来自 165 所高校的学生最终完成,其中电子科技大学以 23 个的学生数量领跑各高校,具体的分布如下所示:
4.2.2 年度贡献分布
除了上述一些统计数据外,我们也希望可以给出一些更加深入的洞察,例如每个高校中不同学生在社区中具体的贡献度等,这种精细化的分析也有助于我们进一步观察学生在整个过程中对于项目的协同参与程度,而不仅仅局限于学生是否仅是完成了一个特定的任务。
注意:受限于 OpenDigger 目前的底层基础数据,下述分析将仅包含 GitHub、Gitee 平台上的数据。
我们使用了 2025 全年的贡献度数据和社区 OpenRank 算法对参与到各社区学生的参与度进行了详细的分析,最终统计到各高校总体贡献度前 20 名如下表所示:
我们在给出了高校总体贡献度的同时也给出了校人均 OpenRank 贡献度,可以看到电子科技大学凭借学生数量与贡献深度的双重提升,成为了 2025 年贡献高校第一名,Top 20 的高校中有 18 所都在去年参与了 OSPP。
为了进一步观察学生的贡献情况,我们也对学生贡献者进行了 OpenRank 贡献度的排名,OpenRank 前 20 的学生如下:
通过对于学生个体的分析,一些贡献度较高的学生就可以清晰的看到。不像往年有些贡献度极高的学生,2025 年大部分学生都保持着相对稳定的新人贡献度水准,可以看出 2025 年吸引到的应该大部分都是新参与到开源中来的同学们。
4.2.3 全域贡献分布
我们可以看到,OSPP 拉动了大量高校的优秀学生在校期间就深入参与到开源社区的贡献之中,那么这些学生是否还深入参与到其他开源社区中,以及他们在全域的贡献度如何呢?我们也统计了这些同学在整个开源的领域的贡献度以及主要贡献项目的情况,如下表所示:
我们可以看到除了 OSPP 的开源社区外,很多同学还大量参与了其他开源社区的贡献。