 2025 中国开源年度报告
2025 中国开源年度报告中国开源年报 2025:商业化篇
前言:
过去几年,中国开源商业化的讨论始终围绕一个核心问题展开:开源项目如何从「被看见」走向「被采用」,再进一步走向「可持续经营」。在此前的商业化篇中,我们更多关注开源企业的商业模式探索,包括开源软件如何通过云服务、企业版、技术支持、生态合作、行业解决方案等方式完成收入闭环,也关注开发者社区、资本市场、企业客户与基金会机制之间尚未完全打通的张力。过去,中国开源商业化的关键词是「验证」:验证开源项目是否能够沉淀真实用户,验证社区影响力能否转化为企业信任,验证国内市场是否愿意为开源背后的服务、稳定性、安全性和长期维护付费。
进入 2025 之后,这一问题并没有消失,但它的背景已经发生了深刻变化。AI 原生技术的爆发、开源模型生态的扩张、云原生基础设施的成熟、企业 OSPO 能力的提升,以及中国开发者在全球协作网络中的持续参与,使开源商业化不再只是软件公司的增长议题,而成为数字产业基础设施、AI 应用供给链和全球技术竞争格局的一部分。
本篇将在过往商业化篇的基础上,继续追问中国开源「如何可持续」,但重点不再停留于商业模式分类,而是进一步分析近年开源商业化范式的重构:一方面,中国开源在 AI、云原生、基础软件、开发者工具和行业应用中获得新的增长入口;另一方面,许可证治理、供应链安全、社区健康度、企业贡献机制、国际合规与资本估值逻辑,也正在对开源商业化提出更高要求。换言之,中国开源商业化已经进入一个新的阶段:从开源项目的商业尝试,走向开源生态的系统经营;从国内市场的产品验证,走向全球协作网络中的能力竞争;从「开放代码」走向「开放创新体系」的商业化组织。
本篇将结合 2025 年数据篇及国内外研究报告,围绕 AI 原生化、全球化、企业治理、投资回报、开源创业和风险合规等维度,分析中国开源商业化的新基础、新机会与新约束。
一、开源商业化的新命题:从项目收入走向生态资产
2025 和今年再讨论中国开源商业化,不能再从「开源项目如何赚钱」这个单点问题出发。更准确的问题应当是:当中国开发者、企业、模型平台和基础软件项目已经进入全球开源生态核心区域之后,中国开源如何把规模、贡献、项目影响力和产业需求,转化为可持续的商业模式、全球协作网络和资本市场认可的生态价值?
这个问题之所以发生变化,是因为开源本身的评价框架发生了变化。《2025 中国开源年度报告:数据篇》开篇指出,开源已经从一种软件开发模式,演变为支撑数字文明的基础性公共基础设施;报告首次全面采纳 OSDGs(Open Source Development Goals)框架,将环境、社会、治理三大支柱纳入开源评估体系,不再只看代码数量或 Star 数,而是关注知识共享、绿色计算、数字主权、标准共建、规则透明和生态健康度等深层价值。这意味着,商业化篇的分析对象也应随之升级:商业化不只是收入模型,更是开源项目能否在公共基础设施、产业供应链、全球治理和开发者网络中获得可持续位置。
数据篇同时给出了一个非常关键的方法论:以**「行为—质量—影响力」**为逻辑主线,先通过 Issue、PR、Review、Merge 等行为识别真实活跃者,再通过社区 OpenRank 判断贡献质量,最后通过全域 OpenRank 衡量全球协作网络中的影响力。这套指标体系对商业化有直接启示:如果一个项目只有下载量、Star 或短期舆论热度,却没有持续贡献、维护者协作、跨组织参与和全球影响力,它很难形成长期商业化能力。反过来,一个项目即便短期收入不高,只要它在关键技术栈中拥有高质量贡献者、多元组织参与和强协作网络,它就已经具备商业化的前置资产。
2025 年的数据说明,中国开源正处在一个非常微妙的阶段:一方面,中国已经是全球开源第一梯队,开发者规模、企业影响力、基础软件项目和开源模型生态都在快速上升;另一方面,中国项目的全球生态引力仍不足,本土项目海外贡献比例偏低,协作网络外部连接度有待增强。这一「能力上升但生态引力不足」的结构性矛盾,正是中国开源商业化的核心命题。
本文的主线由此展开:**中国的开源商业化进入更成熟的阶段:开发者规模与贡献质量提升,推动关键项目进入基础设施层;AI 和大模型爆发,把商业价值从代码分发转向模型复用、推理部署和平台服务;基础软件项目进入全球头部领域,对顶级基金会和企业的影响力更上一层楼;企业贡献和 OSPO 成熟,使开源协作被财务化;资本市场也开始把社区健康度作为估值锚点。**中国开源商业化正在被技术浪潮推向下一个成熟发展的阶段。
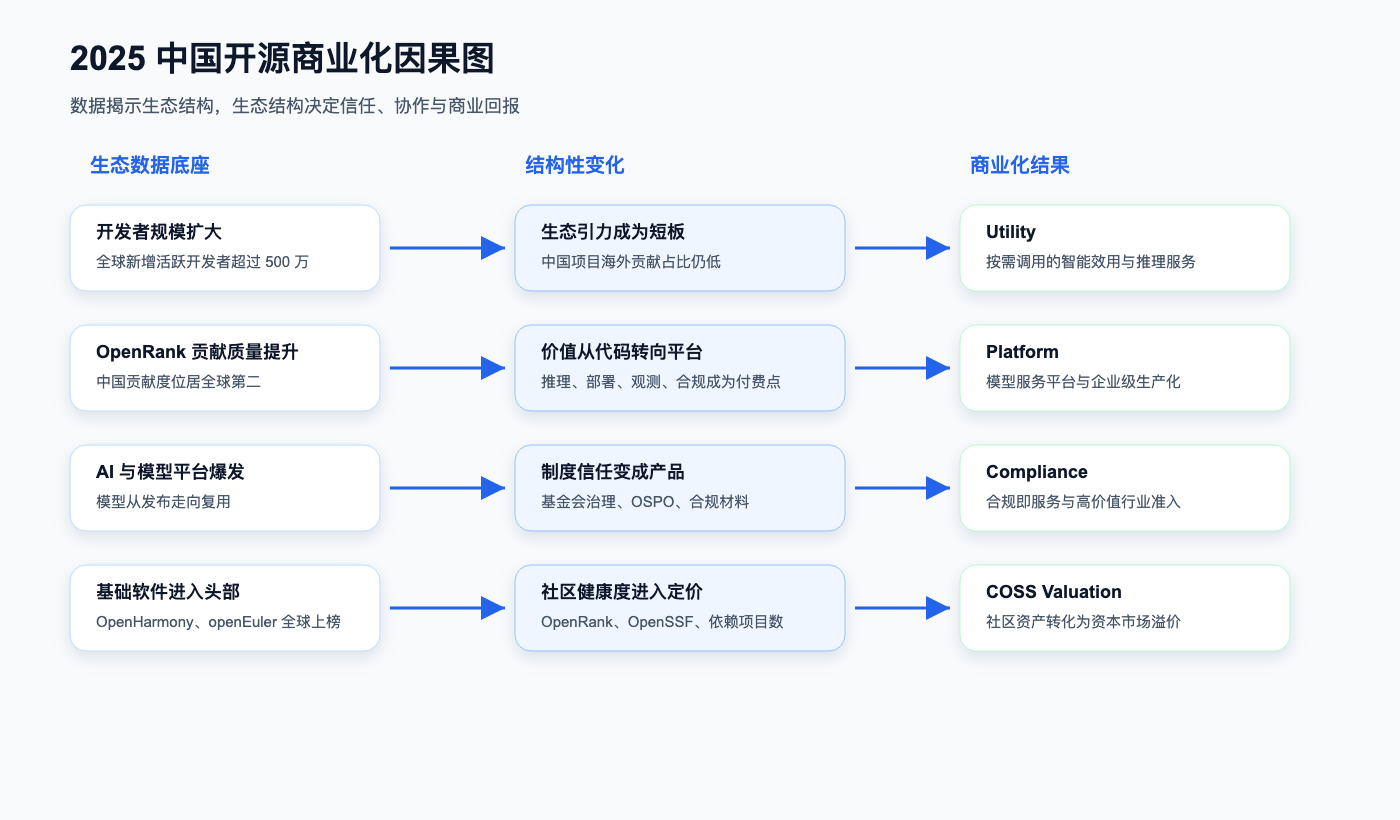
二、开源生态基础:开发者规模、贡献质量与全球协作引力
数据篇显示,2025 年开源生态的第一个基本盘仍是开发者规模。截至 2025 年年底,GitHub 平台活跃开发者累计达到 2,500 万,国内 Gitee / AtomGit / GitCode 等平台活跃开发者规模累计接近 1,000 万,GitLab 平台活跃开发者累计接近 80 万;活跃仓库规模方面,GitHub 超过 3,600 万,国内平台超过 2,600 万,GitLab 接近 73 万,从年度新增看,2025 年全球新增活跃开源开发者超过 500 万,其中 GitHub 平台新增 301 万,国内 Gitee / AtomGit / GitCode 等平台新增整体达到 200 万,GitLab 新增超 12 万。
这些数据对商业化的含义并不是「人多所以市场大」这么简单。更重要的是,开发者规模决定了开源商业化的底层分发效率。传统商业软件需要销售、渠道和客户成功团队逐个触达客户;而开源项目如果能进入开发者日常工具链,就可以通过开发者下载、试用、Fork、贡献、文档传播和社区问答形成低成本扩散。换言之,开发者规模是开源商业化的第一层市场基础。
但规模并不自动产生商业化。数据篇显示,中国在 GitHub 平台活跃开发者超过 210 万,位居全球第三;如果加上国内 Gitee / AtomGit / GitCode 等平台,整体数量预计超过 350 万,位居全球第二。同时,GitHub 上中国新增活跃开发者在 2025 年仅约 1.5 万,而国内平台新增数量去重后超过 100 万。这一变化说明,中国开发者活动正在出现平台结构迁移:全球平台上的新增增速放缓,本土平台上的活跃增长更强。
这会带来一个商业化上的双重结果。正面看,本土平台承接了大量国内企业、个人和高校开发者,为国产基础软件、行业开源和模型社区形成了更强的本地需求池。负面看,如果开发者活动更多发生在国内平台,而国际协作网络连接不足,那么中国项目的全球可见度、海外贡献者参与和国际商业转化会受到限制。因此,中国开源商业化不能只追求国内用户规模,还必须经营全球协作网络。这也解释了为什么后文的「生态引力」会成为核心指标。
数据篇在活跃仓库层面也给出类似信号。2025 年全球活跃仓库规模超过 1,100 万,其中 GitHub 新增 590 万,Gitee / AtomGit / GitCode 等国内平台新增整体达到 500 万,GitLab 新增超 11 万;GitHub 活跃仓库十年间从 223 万增长至 632 万,Gitee 在 2025 年达到约 438.9 万阶段性高点。仓库数量持续增长,说明开源仍处于创新供给扩张期。但商业化真正关心的是:哪些仓库会从「项目」变成「产品」,哪些项目会从「产品」变成「基础设施」,哪些基础设施会形成「生态控制点」。
因此,商业化篇需要把「数据规模」转化为「结构判断」:开发者和仓库的增长提供了开源商业化的市场底盘;平台结构迁移决定了商业化是偏本土内循环还是全球网络化;贡献质量和项目影响力决定了项目能否获得企业客户、基金会和资本市场的信任。
从活跃到贡献:OpenRank 如何改变商业化判断
数据篇使用 OpenRank 贡献度衡量代码提交、评审反馈、问题修复等高质量协作行为,并明确指出它比单纯活跃度更能反映技术共建的深度与可持续性。这对商业化极其重要:企业客户采购开源商业服务时,真正关心的不是项目是否热闹,而是它是否有足够维护能力、响应能力和路线图稳定性。
2025 年全球 OpenRank 数据出现了一个值得警惕的现象:全球 OpenRank 贡献度在 2016-2024 年间由 747 万提升至 2,052 万,但 2025 年下降至约 1,926 万;OpenRank 影响力在 2016-2023 年间由约 2,635 万上升至 9,088 万,2025 年明显降至约 5,640 万。数据篇给出的解释是,生成式 AI 工具广泛应用后,部分原本依赖社区协作完成的任务被技术替代,在提升个体效率的同时,可能降低开发者之间的互动需求和协作频率;同时部分中国开发者转向 GitCode、Gitee 等国内平台,小规模团队和个体项目增多,外部连接度相对减弱。
来自中欧大学和基尔世界经济研究所的研究团队发表了一篇题为《Vibe Coding Kills Open Source》(Vibe Coding 杀死开源)的论文,该论文认为 AI agent 会帮助用户选择、组合和修改开源软件,提升生产率,但也会减少用户直接阅读文档、提交 issue、参与讨论和与维护者互动的机会;如果维护者的回报主要来自直接用户参与,AI 中介化使用可能削弱开源供给。数据篇观察到的协作频率回落,与论文提出的「被使用但不被看见」风险构成因果闭环:AI 提升了开发效率,因此一部分协作被自动化替代;协作互动下降,因此项目维护者更难捕获反馈、声誉和商业线索;维护激励减弱,则可能反过来影响开源项目长期质量。
但中国的数据又呈现另一面。数据篇指出,中国开发者更注重深度贡献:以美国约三分之一的开发者影响力,达到了美国开源开发者贡献度总量的近 50%,且仍以 7.54% 的增速发展;2025 年中国 OpenRank 贡献度位居全球第二,为 254,963,仅次于美国 297,884。这说明中国开源不再只是「使用多」,而是在高质量贡献上接近全球第一梯队。
由此形成第一条商业化链条:中国高质量贡献上升,使中国企业和项目更容易进入全球技术供应链;但全球协作互动下降与平台内循环增强,又削弱了项目的外部可见度和生态引力。因此,中国开源商业化必须从「我能贡献」升级为「我能吸引全球共同贡献」。
这也是为什么企业级开源商业化不能只做功能开发,还必须投入社区运营、开发者关系、英文文档、全球 issue 响应、透明路线图和基金会治理。贡献质量带来技术信任,但开放治理才能把技术信任转化为商业信任。
但笔者相信 2025-2027 年将会是 AI 对于整个软件行业深刻变革的三年,这三年中的开源项目活跃与共线数据,将根据企业开源投入方式、开发者 AI Coding 渗透率和开源项目的主动维护方式的变化而剧烈波动,后文亦有所展开讨论。
从贡献输出到生态引力:全球化商业化的关键短板
数据篇在跨国贡献流向中揭示了中国开源商业化最关键的短板。中国开发者高度活跃于 Linux、Kubernetes、PyTorch 等美国主导的国际主流项目,贡献密度位居全球前列;但反向流动不足,中国本土项目获得的海外实质性参与仍然有限,反映出全球开源协作中的「中心-边缘」结构。
对比中美自主发起项目的贡献分布,这一问题更清楚。美国主导项目中,本土开发者贡献仅占 38.21%,超过六成来自海外,其中中国贡献占 7.81%、德国 6.84%、加拿大 5.06%;而中国主导项目中,本土贡献高达 79.14%,美国贡献仅 6.27%,加拿大 1.59%,国际化协作程度排名第 10。数据篇因此指出,未来开源竞争的核心已从「人才输出」转向「生态引力」,能否吸引全球开发者深度共建,成为衡量国家开源领导力的关键标准。
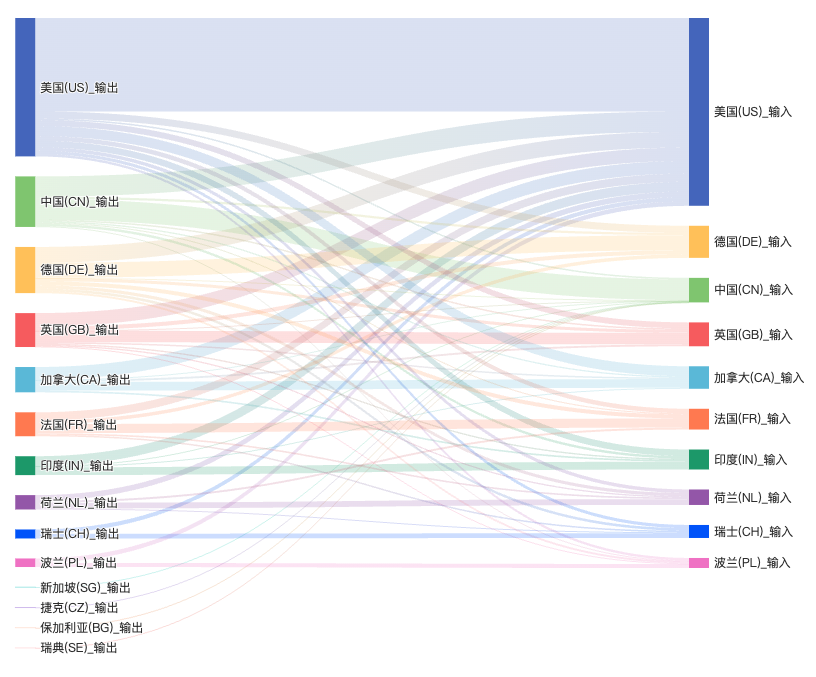
这一点对商业化的影响非常直接。一个开源项目如果主要由本土开发者贡献,它仍然可以在国内形成商业模式,例如政企采购、行业解决方案、国产替代、私有化部署和技术支持。但如果它要成为全球商业开源公司,或者要让海外企业放心把它用于关键系统,就必须证明两件事:第一,项目不是单一公司或单一地区的技术资产,而是可被全球社区共同维护的公共基础设施;第二,项目路线图、许可证、安全响应和治理机制不会因单一商业主体变化而失去稳定性。
这解释了为什么「基金会托管」和「制度安全感」会成为 2025 年商业化篇的重要主题。把 Redis 许可证变更后 Valkey 等项目受到关注的现象概括为「上游时刻」,认为由中立基金会托管的项目能够提供制度性安全感,数据篇关于中美项目国际贡献结构的发现,则从另一个角度证明:制度化治理不是锦上添花,而是中国项目扩大海外贡献、进入高价值市场的前提。
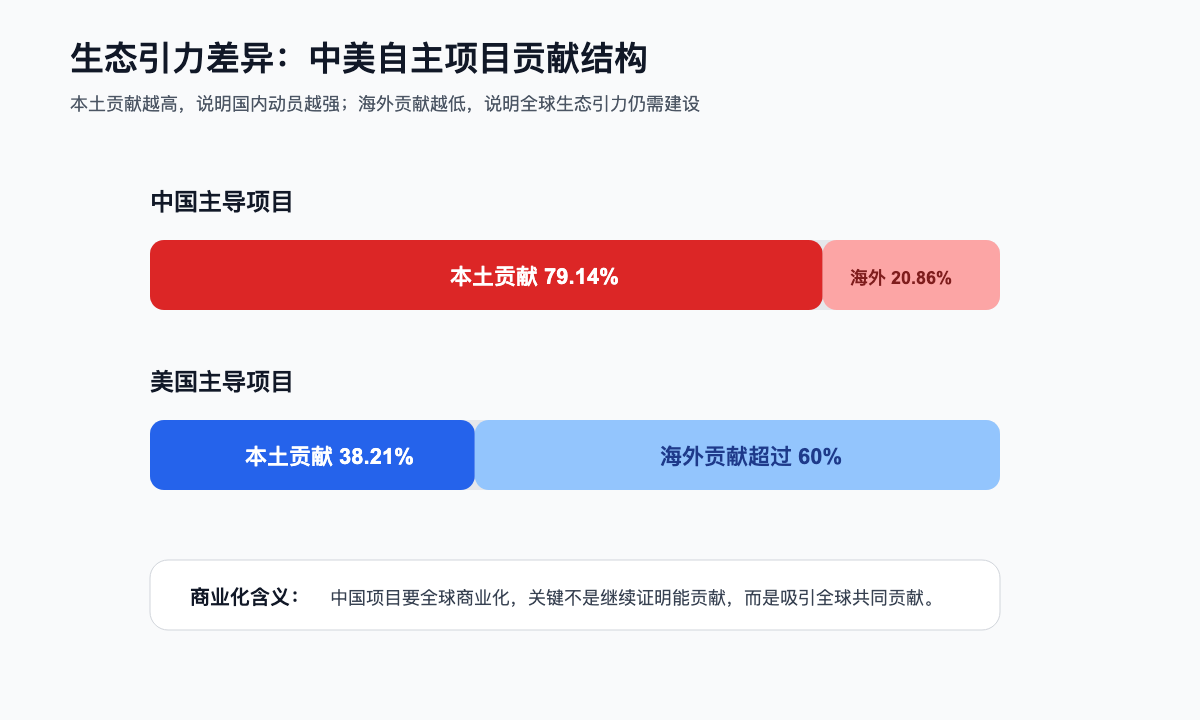
所以,中国项目本土贡献占比高,说明国内产业动员能力强;但海外贡献占比低,说明全球生态引力不足;生态引力不足会限制海外商业采购和国际资本认可;因此,中国开源商业化必须通过基金会治理、透明路线图、国际文档、开放贡献机制和合规能力来降低海外参与门槛。
这也要求中国开源企业重新理解「出海」。开源项目出海不是把 README 翻译成英文,也不是在海外社交媒体上做推广,而是让海外开发者愿意提交 PR,让海外企业愿意把项目放进生产系统,让海外基金会、标准组织和资本市场能够看见项目的治理稳定性与生态韧性。
三、当 AI 进入开源
技术地图:AI 爆发如何改变商业化重心
数据篇显示,AI 大模型已成为 2025 年最大的技术增长极。AI 大模型相关仓库年均增长率超过 210%,并在 2024 年起跃居所有技术领域首位;Qwen、Llama、DeepSeek 等开源模型迅速获得百万级星标,推动「模型即服务」成为新范式,显著降低 AI 应用门槛。与此同时,云基础设施如 Kubernetes、Terraform 持续高活跃,数据库、操作系统、大数据、物联网等基础软件保持稳定增长,构成数字底座。
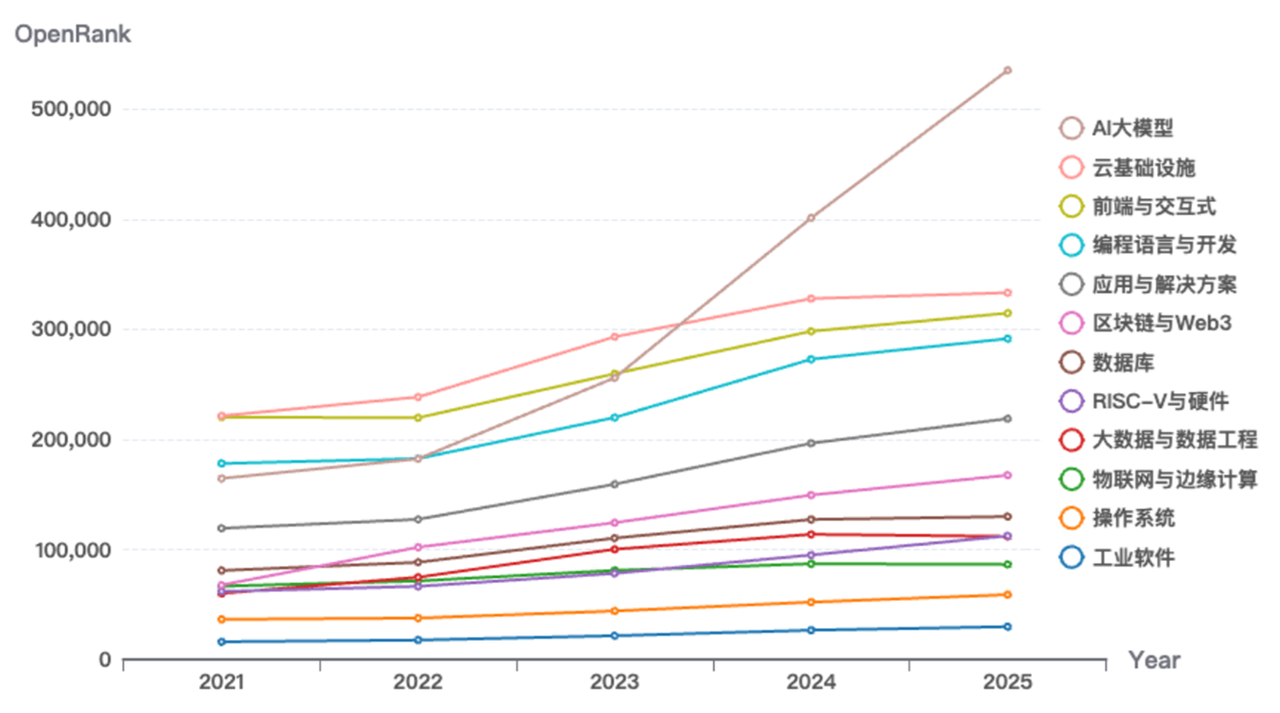
这组数据说明,2025 年的技术结构不是「AI 单点爆发」,而是「AI 引领、云基支撑、根技术筑底」。AI 项目快速增长,带来模型调用、推理优化、Agent 框架、RAG 工具、模型服务平台等新需求;云原生基础设施承接这些新工作负载;操作系统、数据库、编译器、硬件开源和边缘计算,则提供长期稳定的产业底盘。商业化机会也随之从单点软件销售转向多层基础设施堆栈。
CNCF 于今年一月发布的《Annual Cloud Native Survey: The infrastructure of AI’s future》显示,66% 的组织已经使用 Kubernetes 承载生成式 AI 工作负载;但 52% 的组织并不构建或训练 AI 模型,37% 使用托管 API,25% 自托管模型(来源:CNCF, Annual Cloud Native Survey: The infrastructure of AI’s future, 2026, p.6-p.7)。这说明大多数企业不是模型生产者,而是模型消费者和集成者。商业化的高频场景因此不在「训练一个更大的基础模型」,而在「把模型稳定、低成本、安全、合规地接入业务系统」。
这正是开源商业化模式变化的根源。过去开源软件商业化常见路径包括 Open Core、企业版、托管云服务、技术支持和专业服务。AI 原生时代,这些模式仍然存在,但利润重心会向推理成本优化、模型部署平台、私有化和混合云、行业微调、合规审计、模型网关、Agent 工作流、数据连接器和观测平台迁移。也就是说,AI 越普及,企业越需要基础设施化的开源商业服务。
这条链条可以概括为:AI 大模型仓库高速增长,导致模型供给过剩和能力快速扩散;模型能力扩散降低了单一模型稀缺性,推动竞争转向推理效率、部署稳定性和行业集成;企业多数不训练模型而是消费模型,因此推理平台、云原生部署、模型运维和合规服务成为商业化核心。
所谓从「卖软件」到「卖智能」,不是说所有开源公司都变成 API 公司,而是说智能能力会越来越像电力一样被按需使用,而围绕它形成的商业化则包括电网、变压器、计量系统、安全规范和行业接入方案。公共 API 是「电力」,私有化部署是「企业自建变电站」,云原生模型平台是「输配电网络」,合规服务则是「安全认证和监管报表」。
模型平台数据:从「模型发布」到「模型复用」的商业逻辑
2025 数据篇加入 Hugging Face 和 ModelScope(魔搭社区)数据,是商业化篇必须重点吸收的新变化。报告指出,Hugging Face 和 ModelScope 不再只是模型发布与分发平台,而正在演化为同时承载模型供给扩张、开发者协作互动与生态反馈循环的关键基础设施。在大模型生态分析中,数据篇进一步指出,截至 2025 年底,Hugging Face 拥有超过 1,300 万用户和 250 万个模型;ModelScope 吸引超过 1,600 万用户,托管模型超过 15 万个。
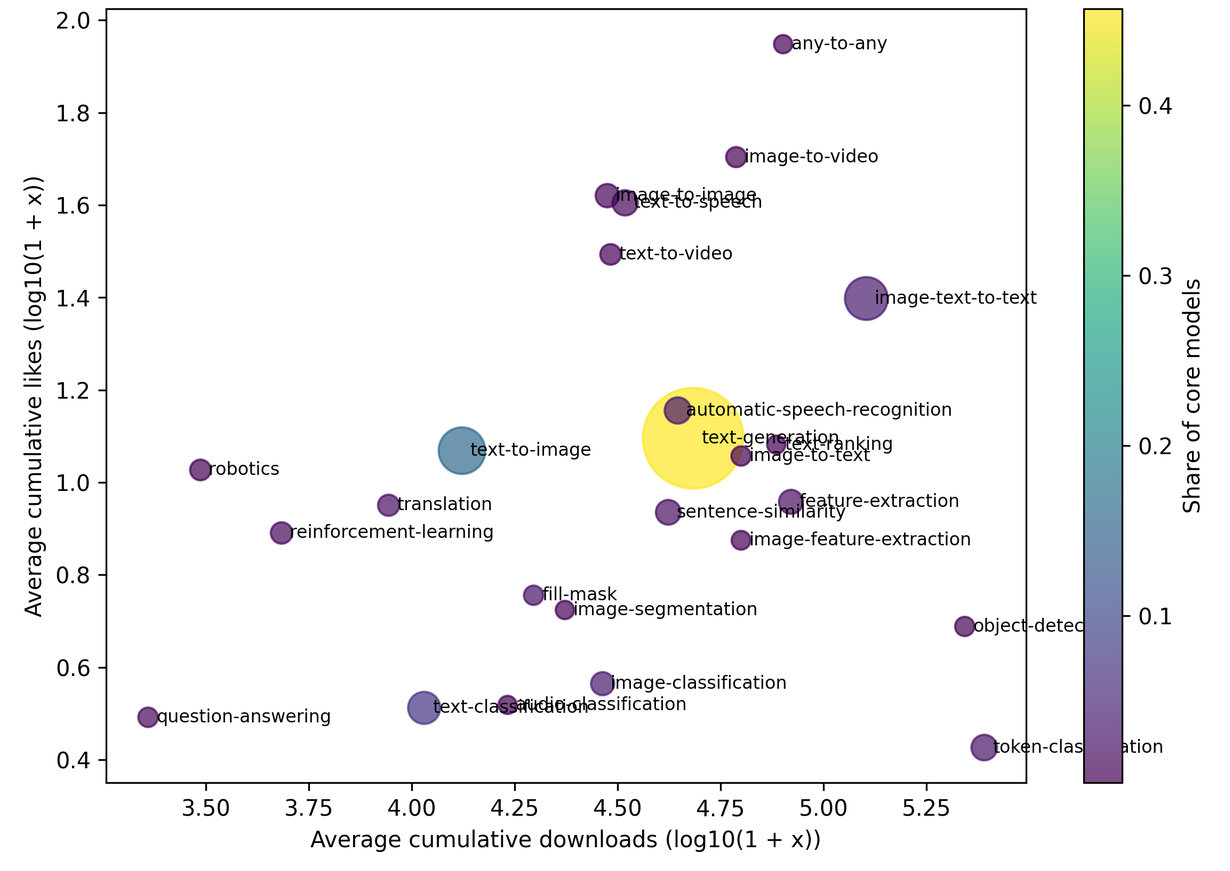
这一变化对商业化极为关键,代码开源时代,商业化围绕软件包、仓库、许可证和部署环境展开;模型开源时代,商业化围绕模型发布、下载、点赞、微调、量化、衍生模型、数据集、推理端点和模型卡展开。模型平台因此成为新的开发者入口,也成为商业开源公司的市场基础设施。
数据篇指出,模型生态正在从「发布」走向「复用」:最近两年,围绕已有模型继续微调、适配和量化的行为明显增加,说明平台重点已不再只是发布新模型,而是围绕基座模型展开持续复用和再开发。这恰恰对应商业化机会的迁移。发布基础模型可以带来品牌声量,但真正可持续的商业价值往往发生在复用环节:企业把模型接入本地知识库、微调成行业助手、量化到边缘设备、优化推理吞吐、接入 Agent 工具链、加上审计和权限控制。
下载量与点赞量的差异,也能帮助理解商业化。数据篇指出,下载更接近模型是否被持续接入产品、脚本、工作流和本地部署方案,点赞更接近模型是否在某一时间窗口获得集中认可;2025 年 11 月 Hugging Face 下载净增达到 42.76 亿次,点赞净增 58.48 万次,2026 年 1 月下载净增升至 507.07 亿次,2 月进一步升至 2,049.69 亿次。换言之,点赞说明热度,下载说明使用;热度可以带来品牌,使用才更接近商业化基础。
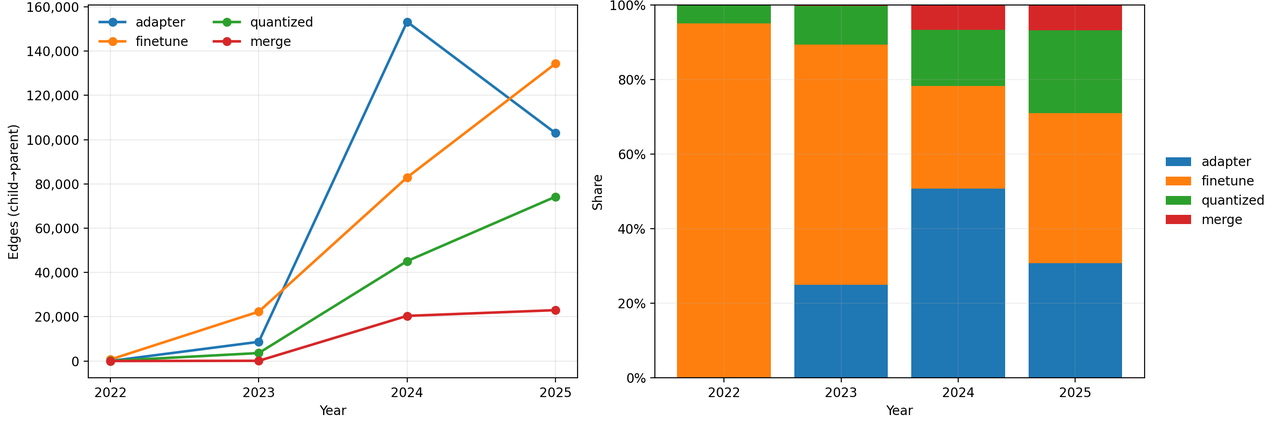
数据篇还指出,中国模型已经从平台活跃参与者转向重要推动力量。Hugging Face 官方综述显示,中国已在月度下载和总体下载上超过美国,过去一年中国模型占平台总下载的 41%,形成最大单一份额;百度在 Hub 上的模型仓库数量从 2024 年零发布增至 2025 年超过 100 个,字节和腾讯发布量分别增长 8-9 倍。这意味着中国模型不只是「被看见」,而是正在被持续使用。
由此形成第三条链条:模型平台规模扩大,使模型分发成本下降;模型下载与衍生复用增加,使商业价值从一次性发布转向持续集成;中国模型下载份额上升,说明中国开源 AI 已进入全球使用链条;但下载和关注不同步,也提醒商业化不能只看舆论热度,而要看模型是否进入长期工作流。
这对中国开源 AI 公司提出了更高要求。一个模型是否商业化成功,不应只看发布当天的 benchmark 和社交媒体热度,而要看:是否有稳定下载,是否被持续衍生,是否被企业集成,是否有清晰许可证,是否能提供推理端点、私有化部署、微调工具、评测体系、安全审计和商业支持。
四、企业开源战略:从技术影响力到产业底座
企业影响力:从「技术补充」到「战略必需」
数据篇明确指出,在中国市场,开源已从「技术补充」升级为「战略必需」。这句话是理解企业商业化的关键。过去企业开源可能是工程文化、招聘品牌或技术传播;现在它已经成为企业争夺开发者入口、技术标准、供应链控制点和 AI 基础设施话语权的战略动作。
全球企业榜单中,Microsoft 以 205,596.64 的 OpenRank 位居第一,Huawei 以 89,368.78 位居第二,Google 以 75,962.65 位居第三;华为成为全球 Top 15 中排名最高的中国企业。数据篇认为,华为在 OpenHarmony、昇腾 AI、KubeEdge 等项目持续投入,使其成为少数能够同时影响基础软件、AI 芯片和物联网生态的中国企业代表。
这说明开源影响力已经与企业基础设施战略深度绑定。NVIDIA 的例子更明显:数据篇指出,NVIDIA 从 2025 年初第 9 名攀升至年末第 4 名,其上升得益于 CUDA 生态、AI 推理优化工具和大模型训练框架等方向的系统性开源布局,成功将硬件优势转化为软件生态竞争力。这对中国企业的启示是:硬件、云、数据库、操作系统、模型能力本身都不足以构成长期护城河,只有当它们通过开源工具链和开发者生态形成事实标准,才会变成商业化护城河。
中国企业榜单呈现出「头部稳固、梯队清晰、新星涌现」。华为以 89,368.78 位居第一,远超阿里巴巴的 26,349.25;蚂蚁集团、字节跳动、百度分列第三至第五;PingCAP、ESPRESSIF、腾讯、Fit2Cloud、DaoCloud 等进入前十。其中,字节跳动 OpenRank 为 16,625.76,同比大幅增长 6,703.16,显示其正从应用层创新向技术底座输出转型
这组企业数据可以拆出三类商业化路径。
第一类是全栈基础设施型。以华为为代表,通过 OpenHarmony、openEuler、MindSpore、昇腾生态、边缘计算和通信协议,构建端、云、芯、框架的整体开源影响力。其商业化不只来自软件收入,而来自生态标准、硬件适配、行业解决方案和自主可控需求。
第二类是云与数据基础设施型。以阿里、PingCAP、SelectDB、StarRocks、Zilliz 等为代表,围绕数据库、湖仓、向量检索、云原生中间件和 AI 数据底座形成商业化。AI 应用越普及,企业越需要高质量数据管理、向量检索和实时分析,这些开源项目的商业价值就越强。
第三类是AI 原生工具链型。以字节跳动、LobeHub、GPUStack、FastDeploy、spring-ai-alibaba 等为代表,围绕 Agent、推理、强化学习、GPU 调度、企业 AI 开发框架和低代码 AI 工具形成增长。这类项目说明商业化机会正在从大模型本体外溢到「让模型可用」的工具链。

这也解释了为什么部分企业排名会波动。数据篇提到 DaoCloud OpenRank 从年初第 6 名下滑至年末第 15 名,跌幅超过 60%,原因包括社区运营与项目迭代未能维持,以及在 AI 原生基础设施热点方向缺乏有影响力的新项目。这一退坡案例很适合放进商业化篇:开源影响力不是一次性资产,而是持续投入的结果。企业如果不能把开源项目与年度技术浪潮结合起来,即便曾经在云原生时代领先,也可能在 AI 原生时代失去开发者注意力。
项目影响力:基础软件商业化正在「基石化」
2025 年全球开源项目影响力榜单出现了一个里程碑:OpenHarmony 以 60,089.18 的 OpenRank 位居全球第一,openEuler 以 16,257.57 位居全球第十;全球 Top 100 开源项目中,美国入选 49 个,中国入选 12 个,位居第二且是唯一进入榜单的亚洲国家。这说明中国开源项目已经不只是局部活跃,而是在基础软件和 AI 领域进入全球头部项目序列。
数据篇指出,OpenHarmony 的得分几乎是第二名 Azure 的 1.5 倍,显示中国在万物互联操作系统领域的巨大投入与生态聚合能力;openEuler 跻身前十,标志中国在服务器操作系统领域占据重要位置。中国项目榜单也显示,OpenHarmony 和 openEuler 分列第一、第二,OpenHarmony 得分超过 6 万,是第二名 openEuler 的近 4 倍,是第三名 MindSpore 的 7 倍以上;openKylin 和 Anolis OS 也位列前列,说明国产操作系统族群正在形成整体厚度。
这背后的商业化逻辑,不能用传统「卖软件许可证」解释。操作系统类开源项目一旦进入端侧、服务器、物联网、车机、工业设备或政企基础设施,它的商业价值就不主要来自软件本体,而来自围绕它建立的兼容认证、行业发行版、迁移服务、长期支持、安全加固、硬件适配、应用生态和治理信任。「基石化战略」:基础设施项目销售的是稳定、安全、合规和长期可维护性,而不是单纯性能。
这也是基金会治理为何重要。OpenHarmony 与 openEuler 都与开放原子开源基金会相关,项目影响力的上升说明中立治理平台能够帮助基础软件聚合企业、开发者和产业伙伴。对关键行业客户而言,项目背后是否有透明治理、开放路线图和多方参与,比单一企业承诺更能形成长期信任。商业化因此不再是「公司拥有一个开源项目并销售企业版」,而是「基金会承载公共底座,商业发行版厂商围绕行业场景提供可信交付」。
中国开源项目 Top 15 还显示,AI 与大模型技术栈成为增长新引擎。MindSpore 和 PaddlePaddle 位居第三、第四,ModelScope 位居第六,VolcEngine 位居第七,verl 位居第十二;这些项目代表中国互联网企业在大模型训练、推理与优化层面的开源投入。数据库与中间件方面,Apache Doris、TiDB、StarRocks、Milvus 等项目持续上榜,说明中国在数据基础设施方面已经形成商业化深水区。
由此形成第四条链条:基础软件项目进入全球头部,说明中国具备构建公共技术底座的能力;公共底座进入关键行业,会把商业价值从软件功能转向可信交付;可信交付需要基金会治理、行业发行版、长期支持和生态认证;因此,基础软件商业化的核心是「基石化」,不是单点产品化。
开源新势力:AI Agent 与推理工具链让商业化进入「场景定义」时代
成熟项目决定底座,新势力项目决定方向。2025 年全球新势力开源项目 Top 30 中,与 AI 相关的项目多达 19 个,占超过一半;其中包括 Cherry Studio、llama.cpp、bolt.new、Roo Code、eliza、cline、aider、OpenHands、goose、modelcontextprotocol/servers、smolagents 等。这些项目的共同特点是,它们不是传统意义上的基础库,而是直接改变开发、部署和人机交互方式的 AI 原生工具。
新势力榜单说明,开源创新正在从「技术组件」走向「工作流入口」。AI 编程助手、Agent 框架、模型上下文协议服务端、桌面 LLM 客户端、全栈应用生成工具,都是开发者与 AI 交互的新入口。谁掌握这些入口,谁就可能掌握下一代开发者工具链的商业化机会。
中国项目跃升榜也体现出类似趋势。verl 位居中国开源项目影响力跃升先锋榜第一,总排名上升 1,582 位;spring-ai-alibaba、ktransformers、kwdb、FastDeploy、gpustack、ha_xiaomi_home、Mooncake 等项目快速上升。数据篇进一步指出,spring-ai-alibaba 将 Agent、Workflow 与多智能体能力集成进 Spring 生态,降低 Java 企业开发 AI 应用门槛;FastDeploy 聚焦大模型推理部署并适配国产芯片;gpustack 解决多模型并发推理中的 GPU 资源调度问题;这些项目共同表明,AI 正从研究原型走向生产就绪。
这里的因果关系很清楚:企业想把 AI 用起来,就需要熟悉的开发框架、低成本推理、国产芯片适配、GPU 调度和行业数据接入;这些需求推动 AI 工具链项目爆发;工具链项目离业务场景更近,因此更容易形成商业化产品和付费服务。
这也意味着中国开源商业化进入「场景定义」时代。数据篇指出,2025 年跃升项目不再追求通用性,而是深度绑定具体场景:从字节团队出品的 RLHF 训练、清程极智、清昴智能等团队围绕昇腾生态合作的一系列推理优化产品和工具,到 KaiwuDB 的物联网数据库、小米的智能家居互联,开源正从「技术展示」转向「问题解决」。这句话非常适合作为商业化篇的核心判断。因为商业化的本质不是「我开源了什么」,而是「我解决了谁的真实问题,并让这个问题在开源网络中持续扩散」。
五、开源价值怎么算:Utility、ROI、OSPO 与资本定价
AI 原生商业模式:从 Open Core 到 Utility、Platform 与 Compliance
基于上述数据,2025 年 AI 原生开源商业化至少出现三种更清晰的模式。
第一种是 Utility 模式:卖智能效用。当模型供给增加、推理成本下降、下载和复用规模扩大,通用模型能力会逐渐从稀缺资产变成可计量资源。企业购买的不是「一个模型」,而是稳定的 token 吞吐、低延迟、可用性、私有化选项、成本可控和 SLA。Linux Foundation 开源 AI 经济影响报告《The Economic and Workforce Impacts of Open Source AI(开源人工智能对经济和劳动力市场的影响)》显示,三分之二受访组织认为开源 AI 部署成本低于专有 AI,近半组织选择开源 AI 是因为成本节约。成本优势会扩大使用规模,使用规模又会推动 API、推理服务、缓存、路由和观测平台商业化。
第二种是 Platform 模式:卖生产化能力。CNCF 《Annual Cloud Native Survey: The infrastructure of AI’s future》调查显示,47% 的组织只是偶尔部署 AI 模型,只有 7% 能每日部署(来源:CNCF, Annual Cloud Native Survey, 2026, p.8)。这说明生产化能力稀缺。围绕 Kubernetes、KServe、Kubeflow、Prometheus、Argo、OpenTelemetry、GPU 调度和模型网关形成的平台服务,会成为开源 AI 商业化的重要承载。模型越多,企业越需要统一平台;平台越成熟,开源项目越容易进入生产;进入生产越深,商业化越可持续。
第三种是 Compliance 模式:卖可信合规。随着模型复用路径增多,数据篇指出模型许可信息完整性问题更加突出,许可是否清晰、是否支持后续复用判断,正在成为平台生态的现实问题。这意味着,开源 AI 商业化不能回避许可证、训练数据、模型卡、衍生模型、风险评估和审计问题。提出「合规即服务」(Compliance-as-a-Service, CaaS),即将 GDPR、SBOM、AI 风险分级、漏洞响应、数据本地化等合规要求内化为产品能力。在高价值行业,合规不只是成本,而是采购前提。
这三种模式可以组合。一个开源 AI 公司可以用开源模型和工具链获取开发者,用低价推理服务形成高频使用,用平台化产品承接企业生产环境,用合规与私有化部署进入金融、医疗、制造和政务客户。商业化的关键不是在开源和闭源之间二选一,而是在开放分发、企业控制、合规信任和持续服务之间找到平衡。
协作 ROI:开源使用方如何获益
商业化篇不能只讨论开源供应商如何赚钱,也要讨论使用方为什么要贡献。Linux Foundation 的开源贡献 ROI 调查《ROI for Open Source Software Contribution》显示,贡献开源在各种参与形式中带来 2-5 倍投资回报;其中代码贡献 benefit-to-cost ratio 为 3.6 倍,社区贡献为 3.2 倍,直接资金贡献为 2.4 倍,基金会贡献为 4.8 倍(来源:Linux Foundation Research, ROI for Open Source Software Contribution, 2026, p.7, p.17)。
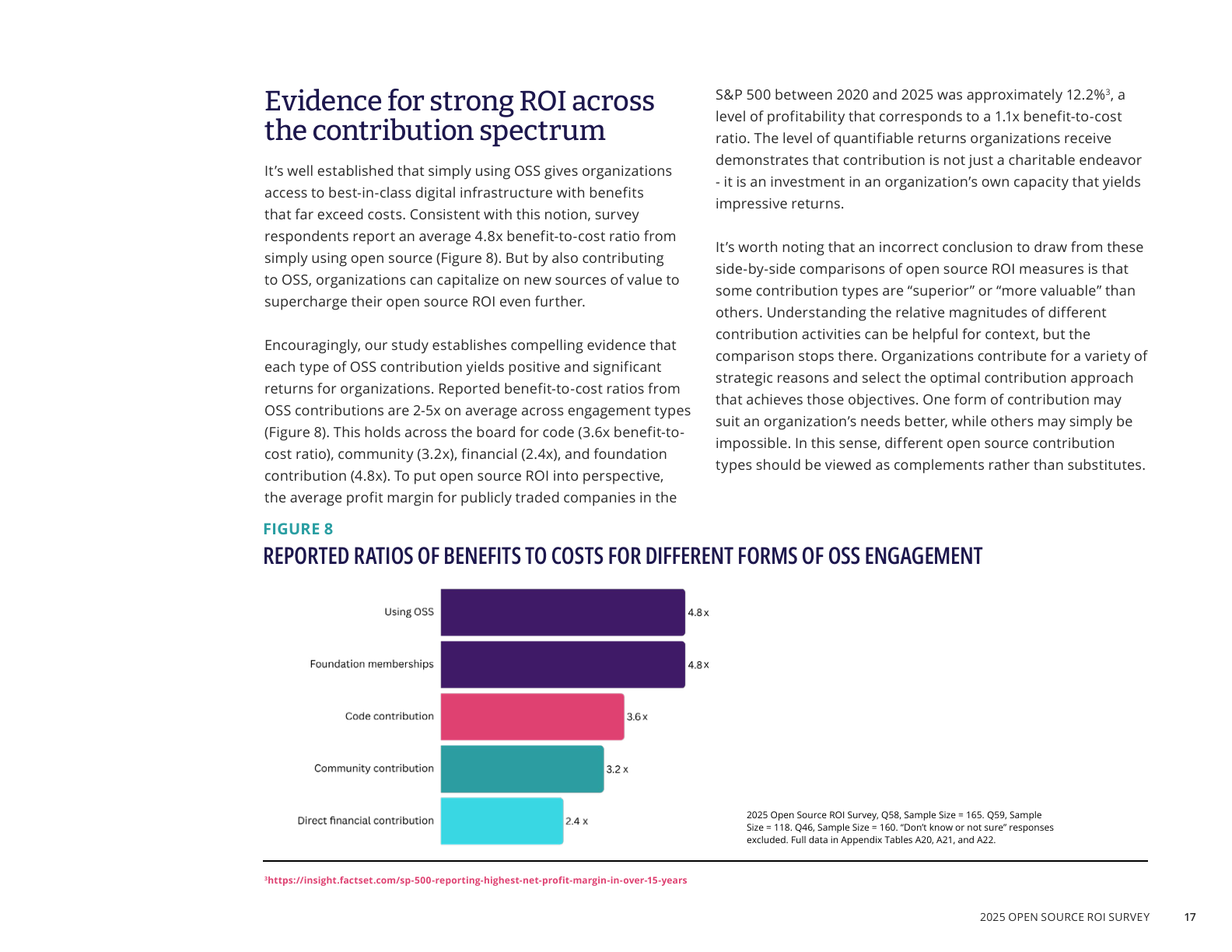
这与数据篇提出的「从使用开源到贡献开源再到引领开源」高度一致。数据篇指出,中国必须突破「内循环」瓶颈,实现从「使用开源」到「贡献开源」再到「引领开源」的跃迁。而 ROI 调查解释了为什么企业愿意这么做:不贡献会产生真实成本。45% 的组织维护 OSS 私有分叉,平均每个组织 86 个分叉,每个发布周期消耗超过 5,000 小时劳动;私有分叉平均每个发布周期需要 5,160 小时、约 25.8 万美元维护成本(来源:Linux Foundation Research, ROI for Open Source Software Contribution, 2026, p.7, p.13)。上下游路线图错位每年平均造成 67 万美元 workaround 成本,大型组织达到 106 万美元。
因此,开源贡献不是公益预算,而是 TCO 优化策略。企业把补丁贡献回上游,可以减少私有分叉维护;参与社区讨论,可以提前理解路线图;加入基金会,可以参与治理并降低供应链风险;提供资金,可以换取项目可持续性和安全响应能力。ROI 调查显示,66% 受访者表示建立贡献关系后,上游维护者对安全问题和 bug 报告响应更快;组织产品开发速度平均提高 10%。
由此形成第五条链条:企业依赖开源越深,私有分叉和路线图错位成本越高;成本越高,贡献上游越具备财务合理性;贡献越多,企业越能影响路线图、提升安全响应、降低 TCO;因此,使用方贡献本身成为开源商业化生态的一部分。
这对中国企业尤其重要。中国企业如果只在全球开源中「使用」和「补丁式贡献」,就难以获得治理话语权;如果能够通过 OSPO、基金会会员、维护者培养、全球社区运营和长期资金支持进入项目核心,就能把技术使用转化为生态影响力,再进一步转化为商业谈判力。
OSPO:从合规办公室到商业化治理中枢
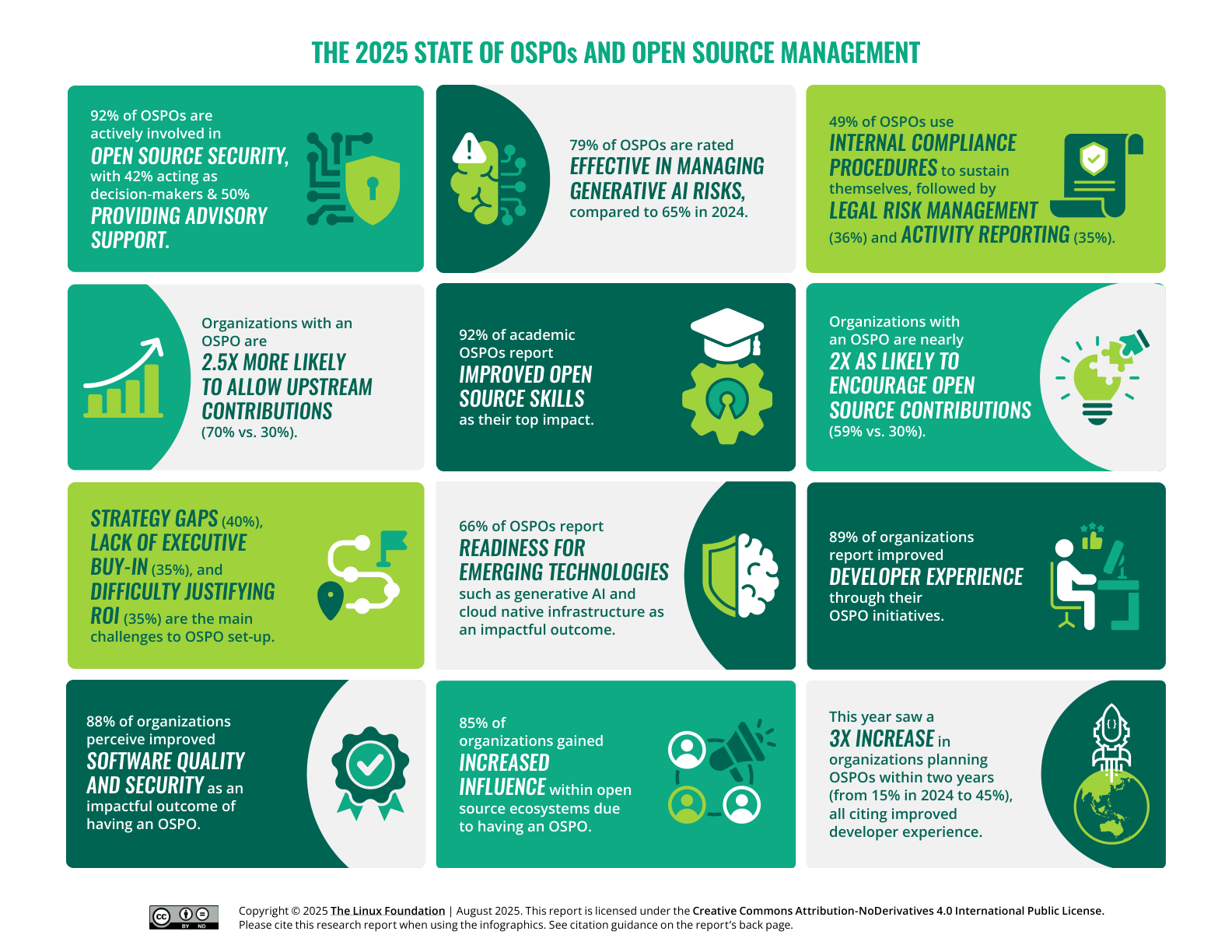
OSPO 是连接企业内部商业目标与外部开源生态的组织接口。Linux Foundation OSPO 报告显示,有 OSPO 的组织允许上游贡献的比例为 70%,无 OSPO 的组织为 30%;有 OSPO 的组织鼓励贡献的比例为 59%,对照组为 41%(来源:Linux Foundation Research, The 2025 State of OSPOs and Open Source Management, 2025, p.5, p.8)。这说明 OSPO 会显著降低企业贡献开源的内部摩擦。
OSPO 的商业化意义不仅在贡献,还在风险管理。报告显示,92% 的 OSPO 参与开源安全,其中 42% 直接参与决策,50% 提供咨询支持;79% 的 OSPO 被评价为能够有效管理生成式 AI 风险,高于 2024 年的 65%;66% 的 OSPO 表示提升了组织对云原生基础设施和生成式 AI 等新兴技术的准备度。
这与 2025 数据篇的合规和模型许可问题直接相连。当模型生态从发布走向复用,企业要判断一个模型能否商用、能否微调、能否部署到敏感行业、能否追溯训练数据和衍生许可,就必须有组织化流程。OSPO、法务、安全、平台工程和业务团队需要共同决定:哪些开源模型可以用,哪些需要隔离,哪些贡献应回到上游,哪些项目值得资助,哪些供应商具备长期可信度。
因此,OSPO 正在成为开源商业化的「采购接口」和「治理接口」。对开源供应商而言,能否与客户 OSPO 对话,能否提供 SBOM、许可证说明、安全公告、贡献政策、治理章程、模型风险文档和合规材料,会直接影响进入大客户的速度。对中国开源项目出海而言,OSPO 不只是海外客户内部的一个部门,而是项目能否通过合规、治理和供应链审查的关键通道。
资本市场:社区健康度正在变成估值语言
开源商业化最终还会进入资本市场定价。Linux Foundation 报告显示,自 2019 年以来,开源技术初创公司平均每年获得约 90 亿美元投资、约 250 笔融资;2024 年,开源技术公司在 211 笔交易中融资 264 亿美元,占所有软件 VC 投资的 5%(来源:Linux Foundation Research / Serena / 开源技术A, The State of Commercial Open Source 2025, 2025, p.2, p.4, p.10)。
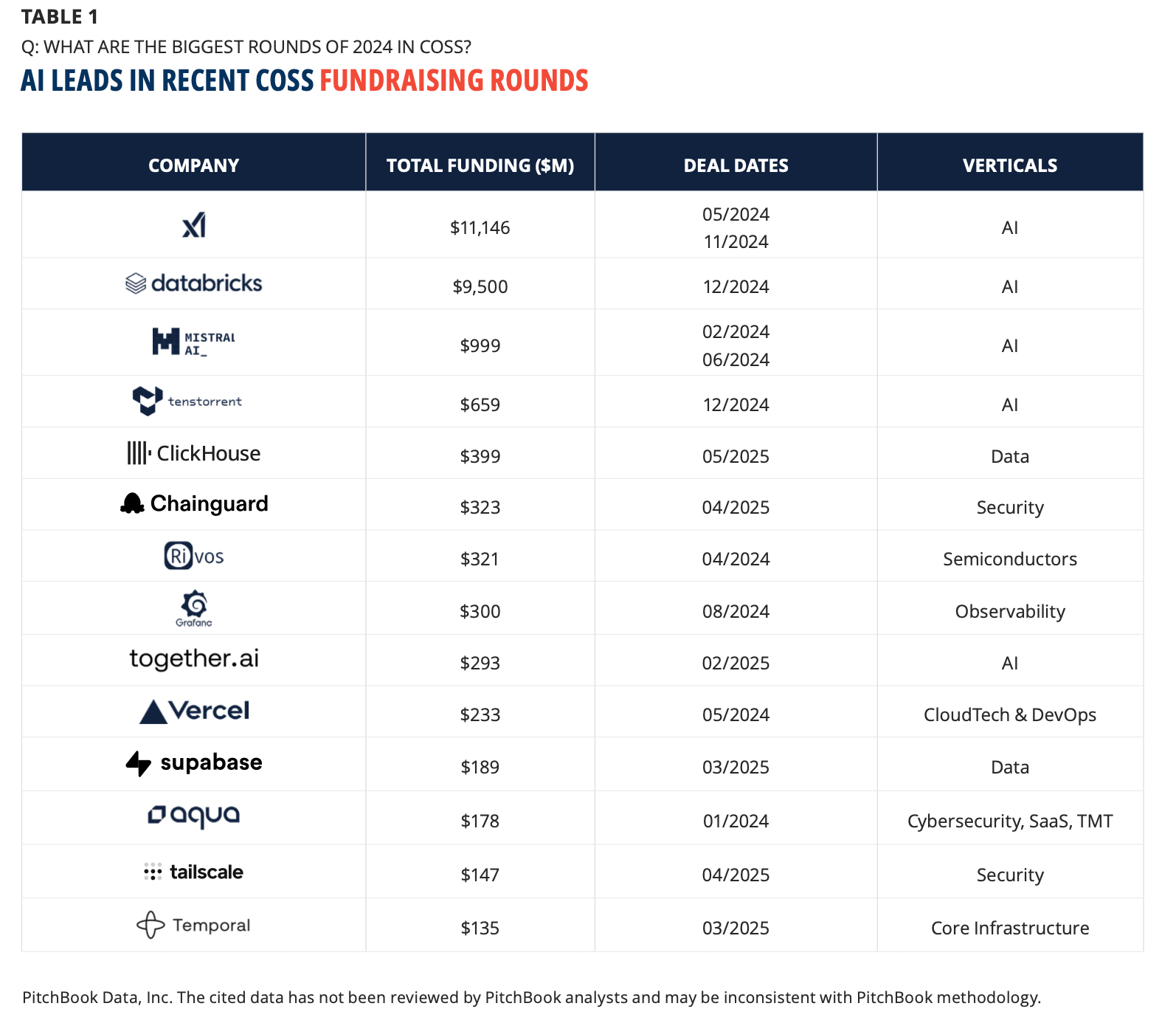
开源技术公司退出表现也显著强于闭源同行。报告显示,12% 获 VC 支持的开源技术公司已经实现 M&A 或 IPO;开源技术 公司 IPO 估值中位数为 13 亿美元,闭源软件公司为 1.71 亿美元;M&A 估值中位数为 4.82 亿美元,闭源软件公司为 3400 万美元。 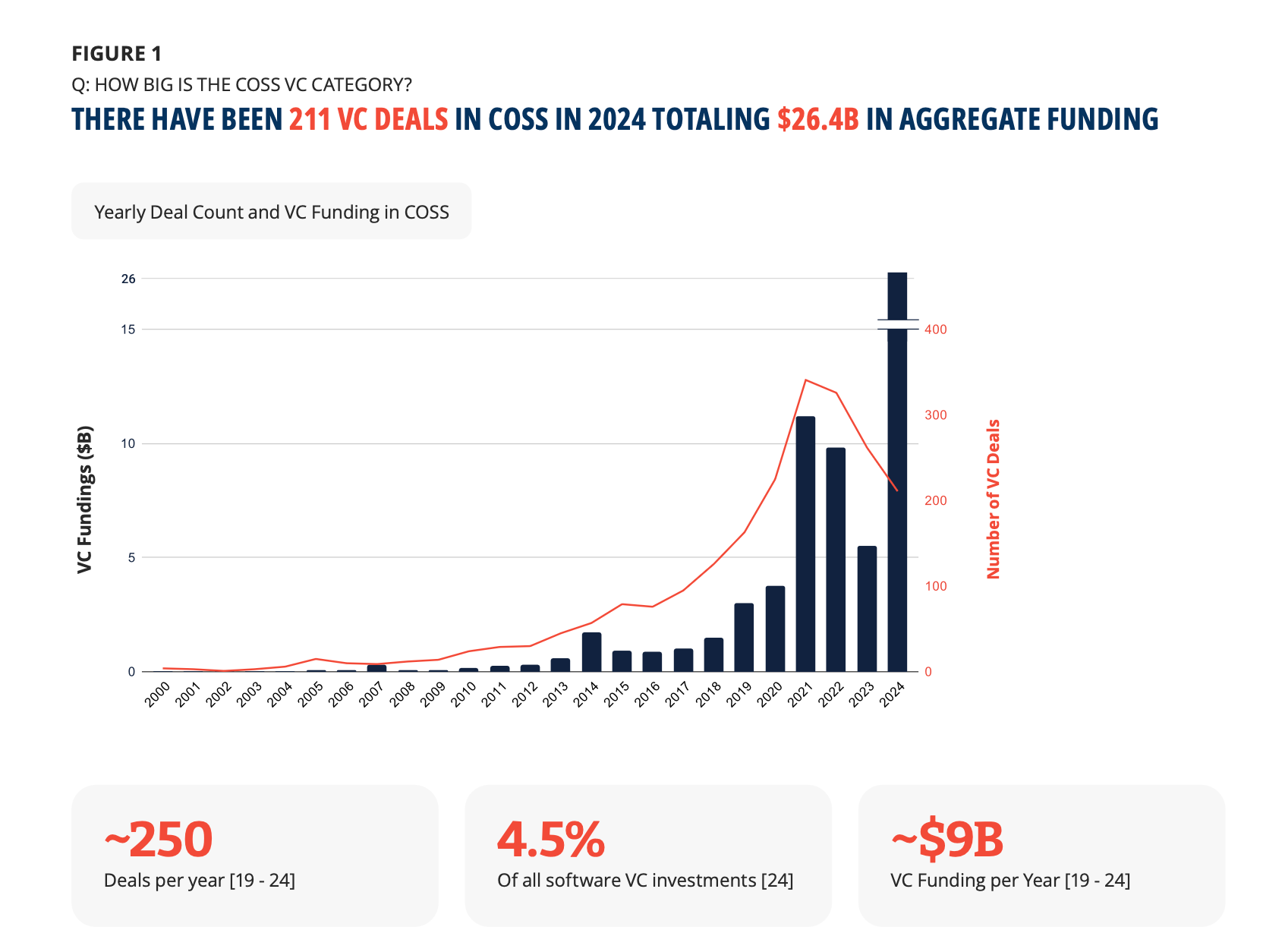
为什么开源公司能获得更高退出溢价?
原因不只是收入,而是社区。技术报告显示,OpenSSF Criticality Score、独立贡献者数量、贡献组织数量、提交频率等指标与开源技术公司估值显著相关,且越到后期融资阶段相关性越强;OpenSSF Criticality Score 在晚期阶段与估值相关性约 0.40,独立贡献者数约 0.41。GitHub stars 能预测估值,但 OpenSSF Criticality Score 的预测表现更强:相对基线解释力从 2.3 倍提升到 3.3 倍,组合模型为 3.5 倍。
这与 2025 数据篇的 OpenRank 方法论形成呼应。OpenRank 强调协作网络和贡献质量,而 开源技术 报告说明资本市场也开始重视类似的深层社区指标。这意味着,中国开源企业未来融资不能只展示用户数、Star、下载量和客户 Logo,还需要展示贡献者多样性、组织参与度、依赖项目增长、issue 响应、发布频率、OpenSSF / OpenRank / 安全健康度等指标。
由此形成第六条链条:开源项目的社区健康度越高,越能证明技术不是单一公司资产,而是生态资产;生态资产越强,战略收购方越愿意为开发者网络、供应链位置和标准影响力支付溢价;因此,社区健康度正在从运营指标变成估值语言。
这对中国开源技术公司是机会,也是挑战。机会在于中国已经有 OpenHarmony、openEuler、MindSpore、PaddlePaddle、ModelScope、TiDB、Milvus、StarRocks 等高影响力项目;挑战在于这些项目需要将社区指标国际化、透明化、可审计化,让海外资本和客户能够理解其生态价值。
六、开源环境:行业场景、区域生态与维护者梯队
行业落地:从「通用技术」走向「高价值场景」
开源商业化的最终落点仍在行业。2025 数据篇中,许多跃升项目已经显示出场景化趋势:KaiwuDB 的 kwdb 面向 AIoT 的分布式多模数据库,支持时序与关系数据融合,已在能源电力、车联网等领域规模化应用;小米 ha_xiaomi_home 推动智能家居互通;gpustack 解决多模型并发推理 GPU 资源调度问题。这些案例说明,开源项目越接近真实业务痛点,越容易形成商业化闭环。
Linux Foundation 开源 AI 经济影响报告也支持行业化判断。报告指出,AI 可能为全球医疗行业带来 1500 亿至 2600 亿美元额外价值,开源模型因成本效率、可扩展性、微调能力和隐私保护而具有吸引力(来源:Linux Foundation Research, The Economic and Workforce Impacts of Open Source AI, 2025, p.4, p.23)。
在制造业,AI 对先进制造的潜在价值为 1700 亿至 2900 亿美元,开放模型因可灵活嵌入运营流程而具备高影响潜力(来源:同上,p.26)。在能源行业,AI 可能带来 1500 亿至 2400 亿美元收入提升,开源工具有助于智能电网、数据整合和信任建设。

这些行业有共同特征:数据敏感、流程复杂、合规要求高、私有化部署强、长期维护需求大。这恰恰是开源商业化的优势场景。闭源 API 可以快速试点,但在医疗、金融、制****造、能源等行业,客户往往需要本地部署、可解释、安全审计、模型可控和长期支持。开源项目如果能提供行业包、合规证明、数据连接器、私有化模型服务和企业支持,就能把开放技术转化为高价值订单。
金融行业则体现了贡献型协作的必要性。ROI 调查中的 FINOS 观点指出,在现代化和 AI 压力下,金融服务行业需要从广泛采用开源转向广泛贡献开源,以降低技术债、增强效率并获得长期技术控制力(来源:Linux Foundation Research, ROI for Open Source Software Contribution, 2026, p.15)。这对中国金融科技、数据库、隐私计算、区块链和风控 AI 项目都有借鉴意义:高合规行业不是不能用开源,而是更需要可信开源。
区域生态:商业化不只发生在公司,也发生在城市群
如果只从企业或项目角度理解开源商业化,很容易忽略一个更底层的变量:城市和区域。开源商业化需要开发者密度、产业场景、资本供给、高校人才、政策支持和社区活动共同作用,而这些要素通常不是均匀分布在全国,而是集中在若干城市群中。数据篇在行政区划影响力排行榜中给出了一个重要信号:全球 OpenRank Top 100 行政区中,美国入选 23 个,德国 10 个,中国与巴西各 8 个,并列第三。这说明中国已经不再只是依赖单一城市参与全球开源,而是初步形成了多区域开源集群。
从中国内部看,数据篇将中国开源生态概括为**「双核驱动、梯度扩散、区域协同」**。北京 OpenRank 为 1,248.72,开发者数量 332.19 万,位居第一;上海 OpenRank 为 1,060.37,开发者数量 244.05 万,位居第二;广东、台湾、浙江、江苏、四川、湖北等进入 Top 15(。这些数据背后的商业化含义,是不同区域正在形成不同的开源商业分工。
**北京的优势在于「基础研究、头部企业和政策资源」叠加。**数据篇指出,北京拥有华为、百度、小米、字节跳动等科技企业总部,也拥有清华、北大、北航、中科院等科研机构,并有海淀、昌平等地的开源产业园和创新基金支持。这意味着,北京更适合孵化 AI 框架、基础模型、操作系统、开发工具和科研驱动型基础软件项目。它的商业化路径往往不是单个产品快速变现,而是通过头部企业、科研机构和政策场景,把开源项目推向国家级基础设施和行业标准。
**上海的优势在于「国际化、金融场景和长三角协同」。**数据篇指出,上海外资企业与跨国公司云集,有助于开源标准对接;同时在 AI 金融、智能投顾、区块链等领域形成特色生态,并与杭州、苏州、南京等地形成研发、应用、服务闭环。这意味着,上海更适合作为开源商业化的国际接口和行业合规试验场。对于数据库、隐私计算、金融级分布式系统、合规 AI、可信供应链等项目,上海的金融客户和国际化环境会形成天然需求。
**广东尤其是深圳,则代表「硬件、物联网、机器人和边缘智能」的开源商业化路径。**数据篇指出,广东位列全国第三,其影响力主要由深圳驱动;深圳在硬件开源、RISC-V、物联网、AI 芯片、机器人等领域持续突破。这说明,广东的开源商业化会更接近「软硬一体」和「端侧场景」:开源操作系统、嵌入式工具链、AI 芯片 SDK、机器人框架、智能家居协议、边缘推理平台,都可能在这里形成从项目到产品再到供应链的闭环。
**浙江与江苏体现「数字经济与智能制造双轮驱动」。**杭州依托阿里巴巴、蚂蚁集团等企业,在云计算、数据库、AI 大模型方向持续发力;苏州聚焦工业互联网、智能制造与边缘计算。这两个区域的开源商业化更可能围绕云原生数据库、企业应用开发框架、AI Agent 工具、工业数据平台、低代码应用和制造业边缘智能展开。
中西部地区则是未来增量。数据篇指出,四川、湖北、陕西等中西部省份展现强劲增长势头,成都、武汉、西安凭借高校资源与产业政策,逐步形成「高校-企业-社区」联动的开源生态,成为潜在增长极。这一点对商业化很关键。开源不仅能服务已有产业中心,也能帮助新兴区域低成本接入全球技术网络,形成区域数字经济的新抓手。对地方政府而言,建设开源生态不是简单办活动或建园区,而是通过开源项目吸引开发者、通过社区连接企业需求、通过高校培养维护者、通过公共平台降低中小企业技术门槛。
因此,区域生态与商业化之间存在明确因果关系:城市开发者密度决定开源项目的早期供给,产业场景决定商业化需求,高校与社区决定长期人才供给,政策与基金决定公共基础设施投入,跨区域协同决定项目能否从地方样板扩展为全国市场。 这也解释了为什么中国开源商业化不应只关注北上广深头部企业,还应关注成都、西安、武汉、合肥、苏州、杭州等区域的新项目、新社区和行业场景。未来能够跑出来的商业开源公司,很可能不是单纯来自互联网大厂,而是来自「地方产业痛点 + 高校人才 + 开源社区 + 专业服务」的组合。
人才供给:开源之夏说明商业化必须投资维护者梯队
商业化不仅需要项目和客户,也需要维护者。开源项目最容易被忽视的成本,是持续维护成本:版本发布、issue 响应、文档更新、安全修复、兼容适配、社区治理和新人培养。这些工作很难在短期商业收入中直接体现,却决定项目是否能长期被企业信任。因此,开源人才培养是商业化的基础设施。
数据篇的开源之夏分析提供了一个重要样本。开源之夏自 2020 年至 2025 年已举办六届,目标是鼓励高校学生参与开源软件开发维护,促进优秀开源社区发展。2025 年,OSPP 总共发布项目 565 个,有学生中选项目 517 个,最终结项项目 436 个,结项率 77%,参与高校 165 所。这组数据说明,中国已经形成了相对稳定的开源新人进入机制。
从商业化角度看,开源之夏的价值不只是「学生完成了项目」。更重要的是,它让学生在真实开源社区中经历 issue、PR、review、沟通、文档和版本协作。这些能力正是商业开源公司最缺的人才能力。企业级开源项目需要的不是只会写代码的工程师,而是能在开放协作环境中与陌生开发者沟通、理解上游规范、尊重社区治理、维护长期兼容性的人。
开源之夏的另一个价值,是让高校成为开源商业化的长期供给端。数据篇指出,电子科技大学凭借学生数量与贡献深度成为 2025 年贡献高校第一名,Top 20 高校中有 18 所去年也参与了 OSPP。这说明开源人才培养不是一次性活动,而是可以形成高校连续投入。对于地方开源生态来说,高校持续参与会带来三个结果:第一,稳定补充维护者;第二,推动研究成果以开源方式进入产业;第三,帮助本地企业以更低成本接触前沿技术。
由此可以形成第七条链条:开源商业化越深入企业生产系统,对维护者能力要求越高;维护者能力不能只靠企业内部招聘,需要高校、社区和项目共同培养;开源之夏这类机制把学生带入真实协作网络,形成未来维护者梯队;维护者梯队越稳定,项目越容易获得企业长期信任。
这条链条也提醒商业化篇不能只写融资和收入。一个开源项目如果没有新人培养机制,短期可以靠核心团队支撑,但长期会面临维护者断层。一旦维护者断层,企业客户会担心安全响应、路线图和版本支持,商业化就会受损。因此,商业开源公司应把人才培养、导师计划、文档贡献、good first issue、社区培训、开源之夏项目设计纳入商业战略,而不是把它们视为社区部门的附属工作。
七、风险与边界:AI 时代的开源商业化不能透支开源公共信任
2025 年的开源商业化不能只讲增长,也要讲风险。数据篇已经提示,2025 年 OpenRank 贡献度和影响力出现同步下滑,可能与生成式 AI 工具替代部分社区协作、开发者平台迁移、小规模团队项目增多和外部连接度减弱有关。这说明 AI 虽然提高个体效率,却可能降低公共协作密度。
CNCF 报告也提出类似担忧:AI 工作负载会对开源基础设施造成机器驱动的自动化使用压力,组织需要通过缓存、资源配额、监控和上游贡献来负责任地使用基础设施(来源:CNCF, Annual Cloud Native Survey, 2026, p.9, p.20)。如果企业只把开源基础设施当作免费资源,却不承担维护、资金和治理责任,就会导致「公地悲剧」。
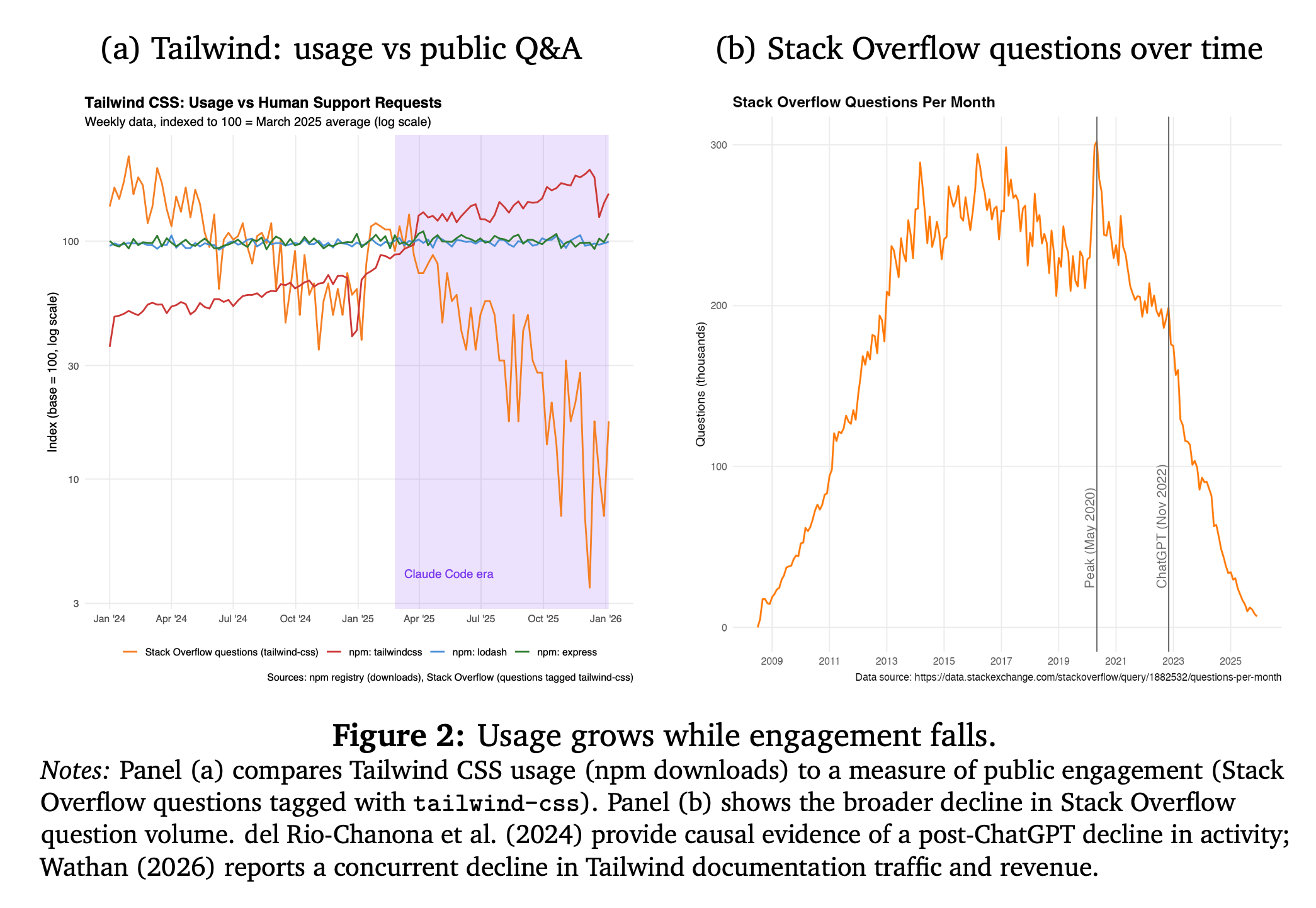
vibe coding 进一步加剧这一问题。当 AI agent 自动选择和组合依赖时,开源项目可能获得更多下载,却失去文档访问、issue 反馈、问答讨论和商业线索。论文《Vibe Coding Kills Open Source》记录了 Stack Overflow 活动在 ChatGPT 出现后六个月内相对减少约 25%;Tailwind CSS 下载量继续上升,但公开问答下降,文档流量较 2023 年初下降约 40%,收入下降近 80%(来源:Miklós Koren et al., Vibe Coding Kills Open Source, 2026, p.6)。
这对商业化提出新的制度设计要求:平台需要让 AI agent 的开源依赖使用更加可观测;企业需要披露、审计和回馈关键依赖;基金会需要探索按使用量、关键度或风险等级支持维护者;商业开源公司需要发展不完全依赖开发者直接互动的企业服务、托管服务和支持模式。否则,AI 会把开源变成更高效的输入品,却削弱维护者获得回报的渠道。
八、开源趋势预测:未来中国开源商业化的五个方向
第一,商业化重心从模型发布转向模型复用与推理生产化。 数据篇显示,模型生态正在从发布走向复用,下载更能反映模型是否进入产品、脚本、工作流和本地部署(来源:数据篇,网页行 823-828, 960-969)。因此,未来商业机会会集中在推理服务、模型网关、RAG、Agent、模型评测、私有化部署、模型安全和合规审计。
第二,基础软件会继续「基石化」。 OpenHarmony、openEuler 进入全球项目头部,说明中国基础软件已经有能力成为公共技术底座。未来商业化不会只靠项目本身,而会靠商业发行版、行业认证、迁移服务、长期支持、硬件适配和生态应用。
第三,全球化的关键从「开发者数量」转向「生态引力」。 中国主导项目本土贡献占比 79.14%,海外贡献偏低;美国主导项目本土贡献仅占 38.21%,超过六成来自海外。因此,中国开源项目要走向全球,必须提高海外贡献者参与,推动治理透明和国际化协作。
第四,企业开源能力会从工程能力变成组织能力。 OSPO 数据说明,有 OSPO 的组织更可能允许和鼓励上游贡献,并更能管理开源安全和生成式 AI 风险(来源:Linux Foundation Research, The 2025 State of OSPOs, 2025, p.5, p.12)。未来开源商业化竞争,不只是项目团队竞争,也会是企业 OSPO、法务、安全、平台工程和开发者关系能力的竞争。
第五,社区健康度会进入资本定价。 开源技术 报告显示,OpenSSF Criticality Score、贡献者数量、组织参与和提交频率与估值显著相关(来源:Linux Foundation Research / Serena / 开源技术A, The State of Commercial Open Source 2025, 2025, p.45-p.47)。OpenRank 与 OpenSSF 这类指标会越来越多进入投融资、并购、采购和政策评估体系。
面向中国开源企业的行动建议
**第一,建立可量化社区指标体系。**企业不应只看 Star、Fork 和公众号热度,而应长期跟踪活跃贡献者、贡献组织数、PR 合并率、issue 响应时长、版本发布频率、下游依赖、下载复用、OpenRank、OpenSSF Criticality Score 等指标。未来这些指标会进入客户采购、基金会评估和资本尽调。
**第二,把英文文档和国际协作当作开源基础设施。**中国项目海外贡献不足,很大程度上与文档、沟通、治理和路线图透明度有关。企业如果想做全球 开源技术,就必须投入英文文档、海外开发者关系、国际社区会议、跨时区维护和开放治理。这些投入短期看像成本,长期看是生态引力建设。
**第三,尽早设计许可证和商业边界。**开源项目商业化最容易在许可证上出问题。企业需要明确哪些部分保持开放,哪些能力作为云服务、企业版、托管服务或合规服务收费;同时要避免频繁调整许可证损害社区信任。许可证不是法务文件,而是商业模式的一部分。
**第四,将 OSPO 能力前置。**无论是大型企业使用开源,还是开源公司对外销售,都需要 OSPO 或类似职能来处理开源引入、贡献、合规、安全和 AI 生成代码风险。没有组织化能力,开源使用会变成隐性风险;有组织化能力,开源贡献才会转化为 ROI。
**第五,把行业场景作为商业化起点。**通用开发者工具适合社区扩散,但高价值收入往往来自行业场景。金融需要合规和稳定性,医疗需要隐私和本地化,制造需要边缘部署和工业数据接入,能源需要安全可信和长期运维。开源项目要从这些行业的真实问题出发,设计产品和服务,而不是只围绕技术特性包装。
**第六,主动参与基金会和标准组织。**中国项目要获得全球信任,需要从公司项目变成生态项目。基金会托管、开放治理、标准参与和多方共建,能降低海外客户的采购顾虑,也能吸引更多贡献者。对基础软件、AI 框架、模型协议、数据基础设施和安全工具而言,这一点尤其重要。
**第七,把 AI 带来的效率红利回流给上游。**企业使用 AI 编程工具越多,越应关注依赖项目维护者的可持续性。可以通过 SBOM、依赖分析、关键项目资助、贡献工时、基金会会员和安全响应合作,把 AI 生产率收益的一部分回流给开源生态。否则,AI 越高效,越可能透支开源公共品。
这些建议背后的共同逻辑是:2025 年之后,开源商业化不再是单个项目的增长技巧,而是一套系统能力。它要求企业同时具备技术产品化、社区治理、全球协作、合规交付、行业理解和资本叙事能力。中国开源已经有足够多的项目和开发者进入全球舞台,下一步需要的是把这些能力组织起来,形成可持续的商业化系统。
「商业化」口径明确为三层:第一层是项目和公司的收入能力,包括云服务、企业版、托管服务、行业方案和技术支持;第二层是使用方的价值回收能力,包括降低采购成本、减少私有分叉、提升安全响应、获得路线图影响力和缩短产品上市周期;第三层是生态层面的价值沉淀,包括标准影响力、开发者网络、区域产业集群、基金会治理和资本市场估值。只有把这三层同时做清楚,才能避免把开源商业化窄化为「卖软件」:数据揭示生态结构,生态结构决定信任、协作和商业回报。
九、案例观察:模型平台、低成本推理与上游信任
2025 数据篇把 Hugging Face 与 ModelScope 同时纳入分析,实际上标志着中国开源年报的数据对象从「代码仓库」扩展到了「模型仓库」。这对商业化篇具有里程碑意义。代码仓库主要承载软件开发协作,模型仓库则承载模型发布、复用、微调、下载、点赞、许可证、模型卡和社区反馈。随着 AI 成为开源创新核心,模型平台正在成为新的开源商业基础设施。
数据篇指出,截至 2025 年底,Hugging Face 拥有超过 1,300 万用户和 250 万个模型,ModelScope 拥有超过 1,600 万用户和 15 万个模型。从规模看,ModelScope 用户数已经具备巨大本土基础;从全球影响看,Hugging Face 仍是国际模型协作的核心平台。中国开源 AI 商业化必须同时理解这两个生态:一个提供全球可见度和国际开发者连接,一个提供本土产业场景和中文开发者基础。
模型平台的商业逻辑不同于传统开源平台。传统代码项目通常通过 GitHub stars、fork、issue、PR、release 来观察热度和协作;模型平台则需要同时看下载、点赞、衍生模型、模型类型、许可证、数据集、推理端点和应用接入。数据篇特别强调,下载量更接近模型是否被持续接入产品、脚本、工作流和本地部署方案,点赞量更接近模型是否在某一时间窗口获得集中关注。这说明模型商业化需要区分「被讨论」和「被使用」:被讨论带来品牌,被使用带来收入基础。
例如,数据篇提到 sentence-transformers/all-MiniLM-L6-v2、google-bert/bert-base-uncased 等模型长期进入下载 Top 20,说明稳定下载需求很大部分来自底层能力组件,它们未必最受关注,却容易被集成到检索、分类、识别、审核和工作流中。而 FLUX.1-dev、DeepSeek-R1 等模型更容易形成点赞峰值,说明它们在某些关键月份获得社区集中认可。这对商业化的启示是:底层组件模型适合做基础设施服务,热点体验模型适合做品牌传播和应用入口,二者不能混为一谈。
对于中国模型公司,真正值得追求的不是单次发布热度,而是长期复用网络。一个模型如果被大量企业下载并嵌入业务流程,就可能围绕它形成量化服务、微调服务、行业适配、推理优化、模型监控、安全评测和合规审计。模型平台越成熟,围绕模型的商业服务就越丰富。未来商业开源 AI 公司的竞争,可能不只是「谁的模型更强」,而是「谁的模型更容易被复用、被部署、被审计、被二次开发」。
DeepSeek 与效用化商业化:低成本不是结论,而是起点
DeepSeek 是 2025 年中国开源商业化绕不开的案例。数据篇在中国开源项目影响力跃升先锋榜中列出 deepseek-ai/DeepSeek-V3,总排名上升 1,233 位,OpenRank 为 394.05,同比增加 370.39。在 Hugging Face 点赞常驻模型中,DeepSeek-R1、DeepSeek-R1-0528、DeepSeek-R1-0528-Qwen3-8B 等也进入榜单,说明 DeepSeek 不只是国内舆论热点,也进入了全球模型社区的关注结构。
把 DeepSeek 放在「推理成本革命」的框架下讨论,认为 MoE、P&D 分离、通信库优化等全栈技术,使大模型部署成本和效率发生显著变化。但在商业化篇中,更重要的是解释因果关系:低成本不是结论,而是新商业模式的起点。
当推理成本下降,原本不经济的应用会变得经济。客服、搜索、办公助手、代码生成、知识库问答、工业质检、营销内容生成、教育陪练、医疗文书、法律检索等场景,都可能从试验走向规模化。使用规模扩大后,客户不再只关心单次 token 价格,而会关心整体吞吐、延迟、稳定性、私有化部署、权限控制、审计日志和成本预测。于是,商业化从模型本体转向推理平台、模型网关、行业方案和运维服务。
这就是效用化商业模式的本质。电力商业化并不是卖发电机,而是卖稳定、可计量、可接入的电力服务;AI 商业化也不只是卖模型,而是卖稳定、可计量、可接入的智能服务。开源模型降低了进入门槛,但企业级客户仍愿意为可靠性、安全性、合规性和场景效果付费。因此,DeepSeek 的启示不是「开源模型免费所以商业化困难」,而是「开源模型降低智能成本后,会打开更大的服务化市场」。
这一点也与 CNCF 调查一致。多数组织不训练模型,而是消费模型;真正的难点在部署、资源管理和生产化(来源:CNCF, Annual Cloud Native Survey, 2026, p.6-p.8)。DeepSeek 这类模型越成功,越会放大下游推理服务、私有化部署、模型压缩、国产芯片适配、模型评测和安全合规的市场需求。
Valkey 与「上游时刻」:许可证变化如何创造信任
商业化篇需要讨论一个看似负面的现象:许可证变化、项目治理争议和供应商锁定,为什么反而会催生新的商业机会。将 Redis 许可证变化引发的市场反应称为「上游时刻」,并把 Valkey 作为制度安全感的典型案例。这个案例说明,当企业把开源组件用于关键系统后,许可证和治理结构本身就会成为商业风险。
对企业客户而言,开源软件的最大价值之一是可控性:能查看代码、能自托管、能避免被单一供应商锁定、能在必要时 fork 或迁移。但如果一个项目长期由单一商业公司控制,并且许可证策略可能随商业目标变化,客户就会重新评估风险。金融、电商、云服务和政企客户尤其敏感,因为它们的系统生命周期很长,迁移成本极高,合规责任也更重。
Valkey 的启示是,中立基金会托管本身可以成为商业价值。基金会不能自动保证项目成功,但它可以降低单一公司控制风险,提供透明治理和多方参与机制。对客户来说,这种制度变化降低了未来许可证突变、路线图不透明和供应商锁定风险。对商业公司来说,围绕基金会项目提供企业发行版、迁移服务、托管服务和技术支持,反而可能获得更大市场。
这也是中国基础软件出海必须重视的问题。如果中国项目希望进入海外金融、云厂商和关键基础设施客户,就必须回答治理问题:商标归谁?许可证是否稳定?谁能合并 PR?安全漏洞如何披露?路线图是否公开?如果主要贡献公司调整战略,项目是否仍能持续?这些问题不是社区细节,而是商业采购问题。制度安全感越强,客户越敢把项目放进核心系统。
结语:从技术领先到商业引领,中间隔着治理与协作
2025 年的数据已经说明,中国开源不再处于边缘位置。中国开发者规模位居全球第一梯队,OpenRank 贡献度位居全球第二,OpenHarmony 位居全球项目影响力第一,华为位居全球企业影响力第二,中国模型在 Hugging Face 下载份额中形成最大单一份额。这些成绩共同证明:中国开源已经具备从技术参与者走向生态塑造者的基础。
但商业化的下一跳,不是简单把这些技术成果包装成产品。真正的跃迁在于三件事。
**第一,要把贡献能力转化为全球生态引力。**中国项目需要更多海外贡献者、更多国际组织参与、更清晰的英文文档和更透明的治理流程。否则,项目可以在国内成功,却难以成为全球商业开源基础设施。
**第二,要把技术底座转化为可信交付。**OpenHarmony、openEuler、MindSpore、ModelScope、TiDB、Milvus 等项目只有通过基金会治理、商业发行版、行业合规、长期支持和生态伙伴网络,才能从开源项目变成可采购、可审计、可持续的企业基础设施。
**第三,要把开源协作转化为可量化商业价值。**贡献 ROI、OSPO 成熟度、OpenRank、OpenSSF Criticality Score、下载与复用数据、依赖项目数量,都将成为衡量开源商业化的新语言。商业化不再只是收入表上的数字,也包括 TCO 降低、供应链风险降低、开发者分发效率、社区健康度和资本市场溢价。
因此,2025 年中国开源商业化的关键词不是「开源 vs 商业」,而是「开放协作如何创造产业级价值」。AI 原生让智能能力降本,云原生让模型进入生产,基础软件让数字主权有底座,OSPO 与基金会让信任可治理,社区健康度让资本能定价。谁能把这些能力组合起来,谁就可能完成从技术领先到商业引领的跃迁。
参考资料与出处
- 开源社,《2025 中国开源年度报告:数据篇》,https://kaiyuanshe.github.io/2025-China-Open-Source-Report/data.html
- 开源社,《2023 中国开源年度报告:商业化篇》,https://kaiyuanshe.github.io/2023-China-Open-Source-Report/commercialization.html
- 《2025年中国开源商业化:AI原生的范式重构与全球化新征程》。
- Linux Foundation, Annual Report 2025.
- Adrienn Lawson and Jeffrey Sica, CNCF / Linux Foundation, CNCF Annual Cloud Native Survey: The infrastructure of AI’s future, January 2026.
- Bianca Trinkenreich and Adrienn Lawson, Linux Foundation Research, The 2025 State of OSPOs and Open Source Management, August 2025.
- Anna Hermansen and Cailean Osborne, Linux Foundation Research, The Economic and Workforce Impacts of Open Source AI, May 2025.
- Sam Boysel and Adrienn Lawson, Linux Foundation Research, ROI for Open Source Software Contribution, February 2026.
- Sam Boysel, Matthieu Lavergne, and Matt Trifiro, Linux Foundation Research / Serena / 开源技术A, The State of Commercial Open Source 2025, August 2025.
- Miklós Koren, Gábor Békés, Julian Hinz, and Aaron Lohmann, Vibe Coding Kills Open Source, arXiv:2601.15494v1, January 2026.